
Dans cet article, je vous présente les différentes sources possibles pour vos reportings. Les solutions natives de vos applications, un datawarehouse ou un datalakehouse ? Je vous propose de passer en revue ces solutions.
Le reporting de données sans la BI
Vos applications sont en général fournies avec des possibilités de reporting dédié fournies par l’éditeur de la solution.
Les avantages de ces solutions de reporting natives sont principalement :
- Le coût normalement inclut dans la solution.
- Des rapports en lien très fort avec les données de la solution.
Par contre les inconvénients sont en général :
- Une faible capacité de customisation et d’intégration de règle spécifique à votre usage.
- L’impossibilité de croiser avec d’autres sources de données extérieures à la solution.
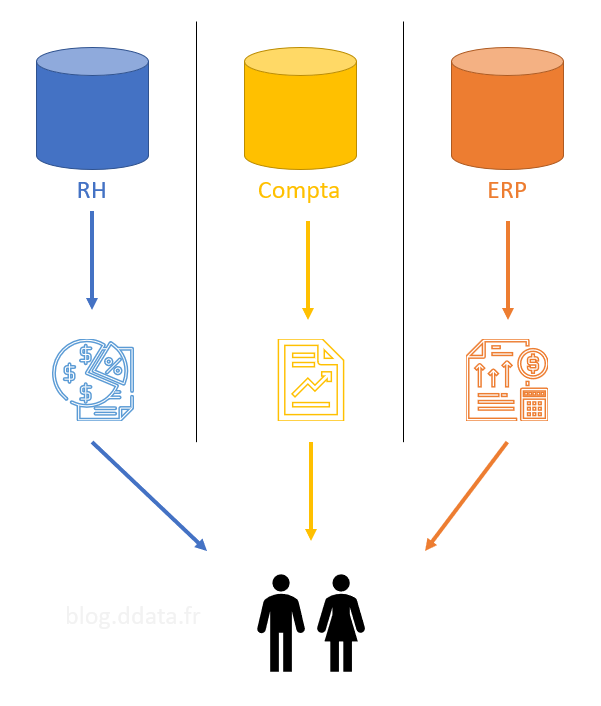
Si l’on faisait une analogie avec la cuisine, nous avons affaire à un plat industriel prêt à être consommé.
On peut donc représenter cette solution avec le schéma ci-dessous avec des applications en silo qui délivre des rapports aux utilisateurs via des outils de reporting différents les uns des autres.
La BI à la rescousse !
Comment faire mieux que cette solution de données en silo ? La réponse est simplement l’informatique décisionnelle souvent appelée BI acronyme de son nom anglais Business Inteligence.
L’objectif de la BI est de vous permettre d’utiliser un seul outil pour tous vos reportings, basé sur une source de données consolidées permettant le croisement des données de vos différents silos de données grâce à la mise en relation des données communes.
Les services attendus d’une couche data
Pour réaliser cet objectif, les solutions proposées par la BI ont évoluée dans le temps, mais les services attendus par cette couche intermédiaire reste les mêmes :
- Capacité de traitement et de stockage dédié distinct de l’infrastructure de l’application
- Centralisation des données
- Modélisation des données optimisée pour le reporting (modèle en étoile)
- Historisation des données
- Pour certaine dimension, il est nécessaire de conserver la trace des changements, on parle en général de dimension à variation lente (Slow changing dimension).
- Pour certaines tables de faits, comme les stocks, on souhaite conserver des photos à un instant T des données afin de les assembler en un film de données permettant de suivre l’évolution des changements dans le temps.
- Réaliser des transformations des données sources comme par exemple passées de données cumulées (non agrégable) en données journalière (agrégable).
Cette liste n’est pas exhaustive des services attendus par les datatrucs.
Les datawarehouses
La solution que l’on retrouve le plus fréquemment dans les solutions BI historiques des entreprises est le datawarehouse ou entrepôt de données en bon français.
Un datawarehouse est basiquement une base de données dédiée au reporting. Cette base de données est chargée via un ETL (acronyme d’Extract Transform Load). Le chargement est en général réalisé par des traitements en mode batch, en opposition à un traitement en temps réel, qui charge les données à une fréquence prédéfinies, classiquement une fois par jour.
Les données subissent des transformations lors du chargement afin que les tables résultantes soient optimisées pour le reporting, on passe en général d’une modélisation OLTP (celle de l’application) à une modélisation en étoile.
Les datawarehouses sont des projets techniques en général réalisés par l’IT de l’entreprise.
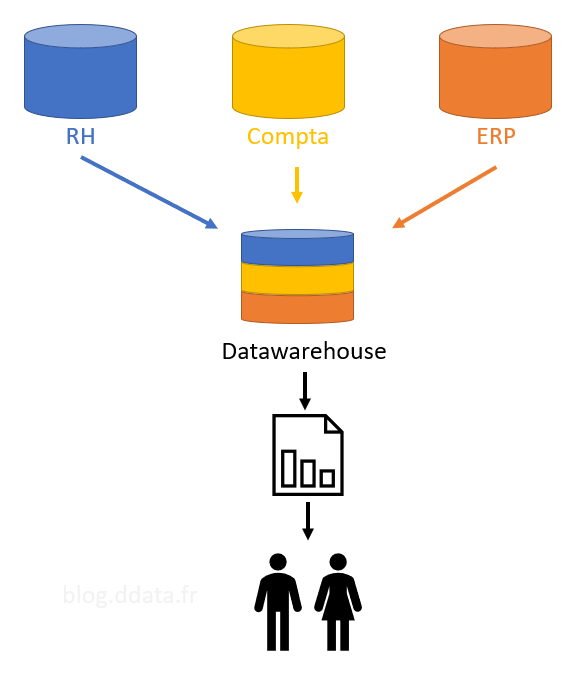
Si l’on faisait une analogie avec la cuisine, nous avons affaire à un plat fait maison, mais l’œuf utilisé pour la tarte ne peut plus servir à faire des crêpes.
On peut donc représenter cette solution avec le schéma ci-dessous avec des applications en silo qui sont chargées dans une base intermédiaire dédié au reporting, le datawarehouse.
Le reporting peut être réalisé par un outil unique ou pas en fonction des besoins des utilisateurs.
Les datalakehouses
Les datawarehouses ont certains inconvénients et ne sont pas optimisés pour répondre à certains besoins modernes :
- Les données étant stockées dans une base de données, ils supportent très mal les données non structurées et les changements de structure des données dans le temps.
- Les données de type streaming (données en temps réel comme un capteur ou flux de données twitter) sont difficiles à intégrer dans un datawarehouse.
Pour répondre à ces besoins modernes tout en gardant les services fournis par les datawarehouses, la BI moderne propose comme réponse les datalakehouses.
Un datalakehouse est la fusion des datalakes et des datawarehouses. J’ai expliqué ce qu’est un datawarehouse ci-dessus, je vais donc expliqué le concept de datalake.
Les datalakes sont la réponse au stockage de données répondant aux critères suivants :
- Il accepte les formats multiples
- Données structurées en provenance des bases de données
- Données semis structuré comme des fichiers Excel, JSON, CSV
- Données non structurées comme des images ou vidéos, qui pourront subir des traitements de type IA pour en extraire de l’information exploitable.
- Il supporte des fréquences de chargement variables allant du mode batch de datawarehouse au temps réel.
Ce stockage permettant tous ces cas d’usages n’est ni plus ni moins qu’un stockage avec les mêmes services qu’un disque dur, mais disponible en général dans le cloud.
Le plus important avec un datalake est la rigueur avec laquelle on range ces données afin de ne pas finir avec un dataswamp ou marais de données.
Un datalakehouse est donc une architecture de raffinage de données composé d’un datalake et de divers outils permettant le raffinage des données. Différents outils peuvent être utilisés aux différentes phases de raffinage en fonction des besoins.
Les principales étapes de raffinage des données sont :
- L’alimentation du datalake avec les données brutes, sans transformation, dans une zone que l’on nomme couramment Bronze.
- Le raffinage des données brut à l’aide de divers traitements en fonction des besoins, on stocke le résultat dans une zone que l’on nomme couramment Silver.
- La mise à disposition des données de reporting dans une zone que l’on nomme couramment Gold. Les données peuvent par exemple être préaggrégées pour améliorer le reporting.
On conserve les données de chaque étape ainsi on peut, si besoin, ajouter de nouveaux traitements sur d’anciennes données.
Les données du datalake du dalakehouse seront donc disponibles pour d’autres usages tels que :
- Du machine learning.
- Un référentiel d’entreprise mis à disposition d’autres applications.
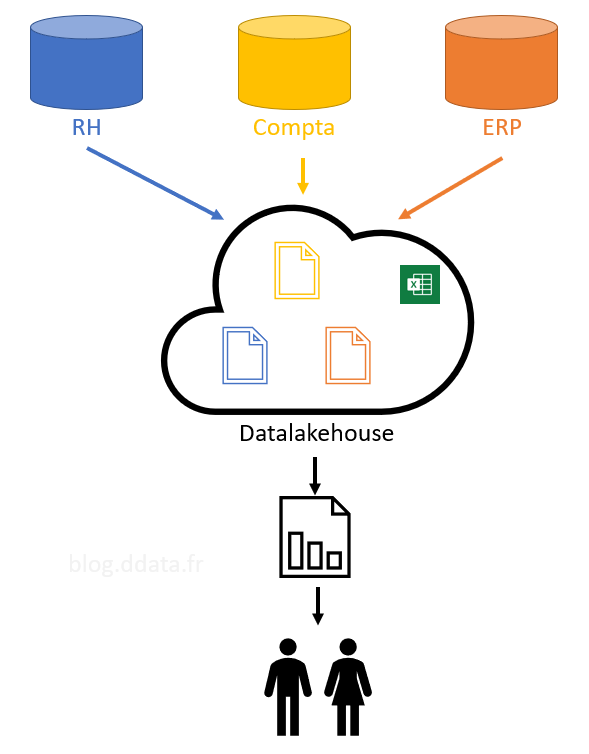
Si l’on faisait une analogie avec la cuisine, nous avons affaire à un garde-manger où on en prend les éléments que l’on souhaite cuisiner en fonction des besoins.
On peut donc représenter cette solution avec le schéma ci-dessous avec des applications en silo qui sont chargées dans un stockage intermédiaire sans usage spécifique puis préparé en fonction des besoins, notamment le reporting.
J’espère que maintenant vous comprenez mieux l’utilisation de ces différents datatrucs.
Merci de votre attention.