
Vous travaillez avec des données ? Il est temps de parler modélisation de données.
Avertissement
Je commence ici une série d’articles portant sur la modélisation de données.
Mon objectif est d’initier toutes personnes devant travailler avec les données aux notions de base de la modélisation, je m’adresse donc aux personnes ayant peu ou pas du tout de notion dans ce domaine.
Je vais donc me permettre d’être incomplet, voire même simpliste, le but n’étant pas de faire de vous des maitres de la modélisation, mais juste de vous apporter les bases afin de comprendre les enjeux et l’importance de la modélisation quand on travaille avec les données.
Pourquoi modéliser les données

Commençons par une analogie avec le monde animal, vos données sont des ressources et vous pouvez soit faire comme le bousier, accumuler vos ressources pour en faire une boule qui aura son utilité, mais principalement en surface, soit organiser vos ressources comme une abeille et les transformer en nectar.
La modélisation de données va vous permettre de passer du bousier à l’abeille 🤩.
La modélisation c’est quoi ?
La modélisation des données c’est simplement le fait d’organiser et de structurer vos données d’une manière spécifique afin de répondre à votre besoin. En général le résultat de la modélisation est un ensemble de tables organiser selon une certaine logique.
Les 3 grands types de modélisation
Il existe plusieurs manières de modéliser les données. La première chose à comprendre c’est pourquoi nous avons différentes manières de faire. La réponse est simple : nous avons des besoins différents :
- Quand vous réaliser une application classique, avec Power apps par exemple, vous allez faire beaucoup d’écriture de données, à chaque enregistrement et beaucoup de lecture unitaire, à chaque fois qu’un utilisateur ouvre un enregistrement. Cet usage demande pour être performant d’avoir des tables le plus segmentées possible afin de ne pas avoir de redondance de données afin d’optimiser les multiples lecture et écriture. Il en ressort en général un modèle avec beaucoup de tables reliées entre elles avec des relations.
- Quand vous faite du reporting de données, avec Power BI par exemple, vous allez faire une seule écriture de données, lors du chargement du modèle et beaucoup de lecture massive voir totale des données. Dans ce cas un grand nombre de tables avec un grand nombre de relations pénalise les performances. Pour résoudre ce problème, nous allons modéliser nos données différemment que pour l’application source de la donnée.
Pour les applications classiques
Pour les applications classiques, nous allons faire une modélisation de données ayant pour but d’éviter la redondance de données et garantir la cohérence de nos données. On parle en général de modèle relationnel.
En termes de méthodologie de modélisation, vous retrouverez principalement la notion de formes normales et de modélisation selon la méthode Merise pour les plus anciens.
L’objectif de cette modélisation est de garantir le caractère ACID des transactions d’écriture des données :
- A - Atomicité : La propriété d’atomicité assure qu’une transaction se fait au complet ou pas du tout.
- C - Cohérence : La propriété de cohérence assure que chaque transaction amènera le système d’un état valide à un autre état valide.
- I - Isolation : Toute transaction doit s’exécuter comme si elle était la seule sur le système.
- D - Durabilité : La propriété de durabilité assure que lorsqu’une transaction a été confirmée.
Pour le reporting
Schématiquement, lorsque vous faites du reporting, vous ne faites qu’une seule écriture en masse de votre base, comme pour le chargement d’un datawarehouse par un ETL ou le mode import de Power BI. Puis vous réalisez exclusivement des lectures sur un très gros volume de données.
Vous allez donc optimiser votre modélisation pour être performante en lecture et croisement de données, or ce qui est couteux pour ce genre d’opération c’est un grand nombre de relations entre les tables.
C’est pour cette raison que nous modélisons les données pour Power BI suivant le modèle en étoile. Ce modèle est centré sur des tables de faits et des tables de dimensions. Généralement les tables de faits vont provenir de systèmes différents et nous allons faire communiquer entre elles les différentes tables de fait grâce aux dimensions qu’elles ont en commun.
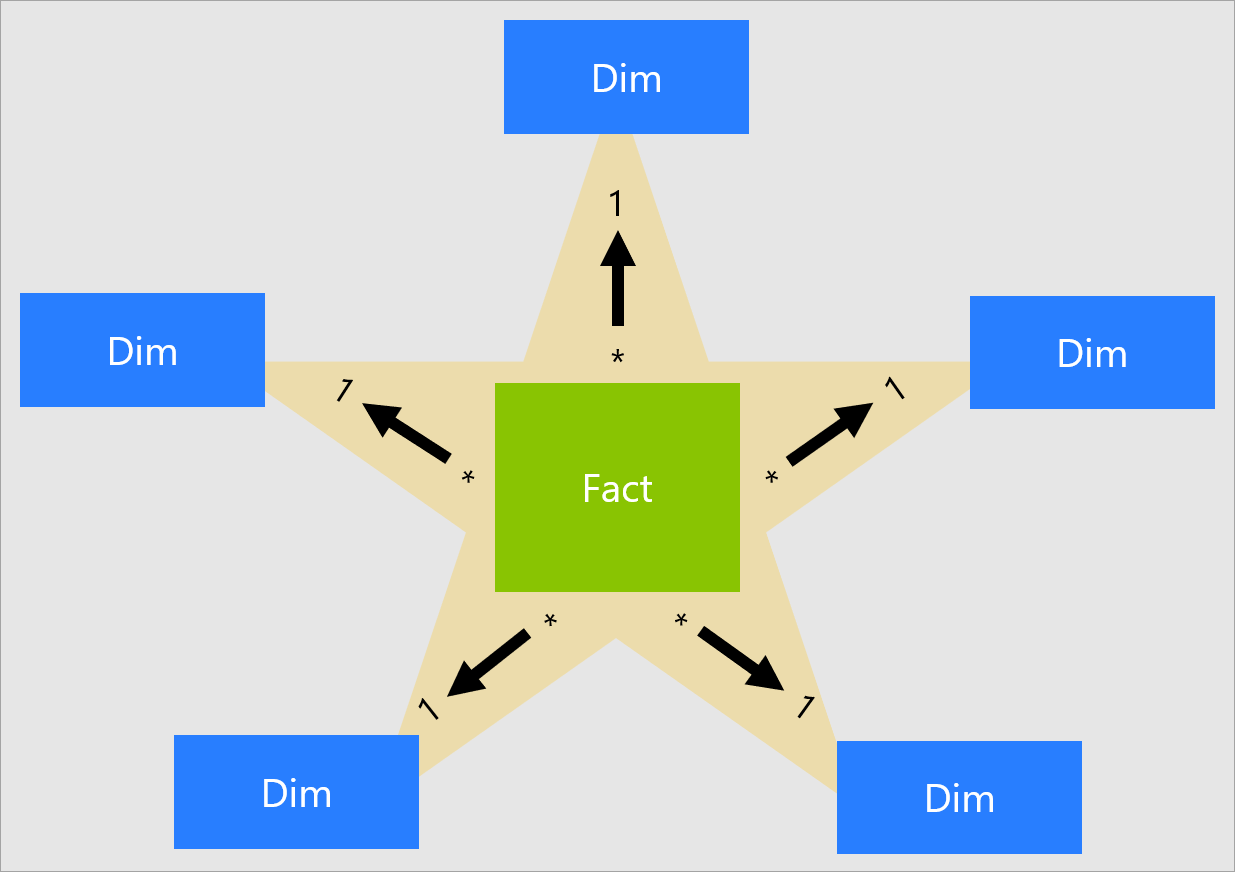
Pour les applications distribuées
Pou les applications distribuées, application dans le cloud nécessitant de fortes montées en charge et/ou des croissances exponentielles, nous allons faire une modélisation de données ayant pour but de permettre la monter en charge. Un moteur de base de données classique ne peut que faire de la croissance verticale. Si vous avez besoin de plus de puissance, vous utilisez une machine plus puissante. Ce modèle a des limites aussi bien physiques qu’économique, plus une machine est puissante, plus elle est chère.
Pour absorber des montées en charge exponentielles, le cloud propose des architectures permettant une montée en charge horizontale. Pour montée en puissance vous ajoutez des machines peu chères puis vous les retirez quand vous n’en avez plus besoin.
Cela fonctionne bien avec les bases NoSQL (Not Only SQL). Ces bases proposent une modélisation différente des 2 précédentes. Pour faire simple, ces bases ne vont pas avoir le même niveau de service que les bases de données relationnelles traditionnelles et vont par exemple être optimisées pour des usages très particuliers. Par exemple une base comme MongoDB va proposer de stocker l’ensemble des données d’un client pour un site de e-commerce dans un seul document de type JSON. Ce document aura des données redondantes par rapport aux autres documents en base pour les autres clients. Mais chaque client pourra modifier son propre document, lors d’une nouvelle commande par exemple, sans créer une contrainte sur l’ensemble de la base, mais uniquement sur son document.
Parcour Microsoft Learn - Implémenter un modèle de données non relationnelles
Merci de votre attention.