
On continu le match avec un vieux compagnon le SQL.
Contexte
Afin de découvrir les différents types de traitement proposé par Microsoft Fabric, je vous ai proposé un match entre 3 différentes possibilités : Préparation de données avec Microsoft Fabric, le match !.
Je me propose ici de réalisé les transformations avec du SQL.
Pour rappel, le langage SQL est le langage utilisé pour interagir avec les bases de données. Il permet d’interroger les données contenues dans des tables et permet aussi de réaliser des modifications sur les données.
Création de notre table SQL
Dans le cadre de Microsoft Fabric, nous avons 2 possibilités pour utiliser le SQL :
- le point de terminaison SQL du lakehouse permet de faire des requêtes seulement en lecture sur les fichiers managés. C’est les fichiers présentés sous la forme de table.
- le warehouse qui permet de gérer une base de données complète en gérant à la fois les requêtes de lecture que de modification de données.
Pour le match, j’ai choisi d’utiliser le point de terminaison SQL du lakehouse.
La première étape est de transformer notre fichier non managé en table. Une table dans le point de terminaison SQL est un fichier en mode managé sur lequel on peut réaliser des requêtes SQL.
Ouvrez le lakehouse LeMatch de l’espace de travail Fabric - Le match [Silver].
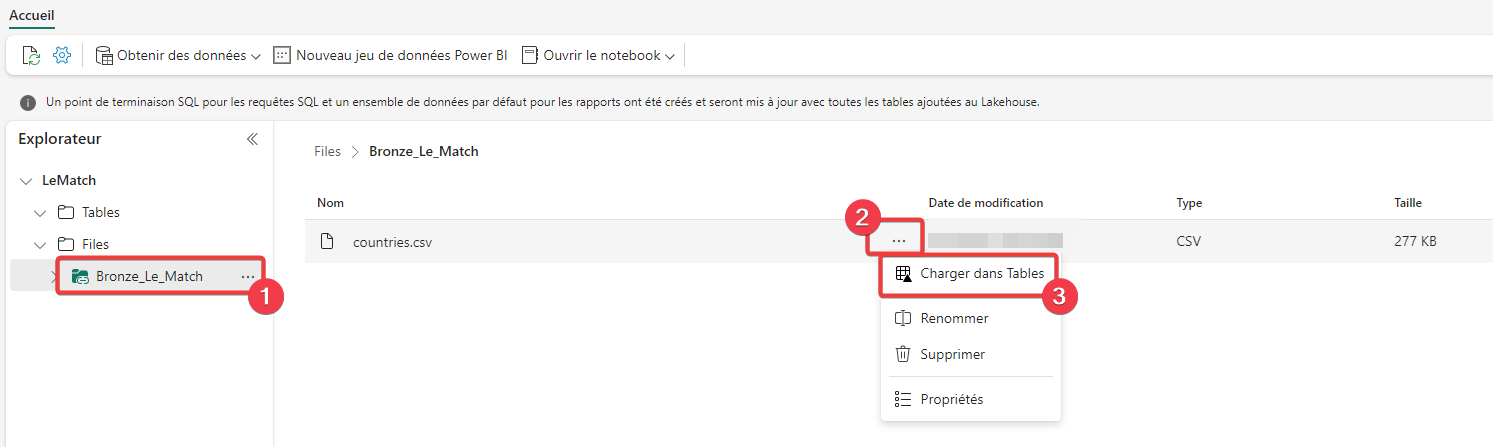
- Rendez-vous dans le dossier du raccourci Bronze_Le_Match.
- Sélectionnez les 3 points sur la ligne du fichier.
- Dans le menu, choisissez Charger dans Tables.
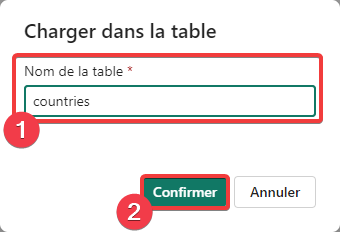
- Entrez countries dans le nom de la table
- Appuyez sur Confirmer pour continuer.


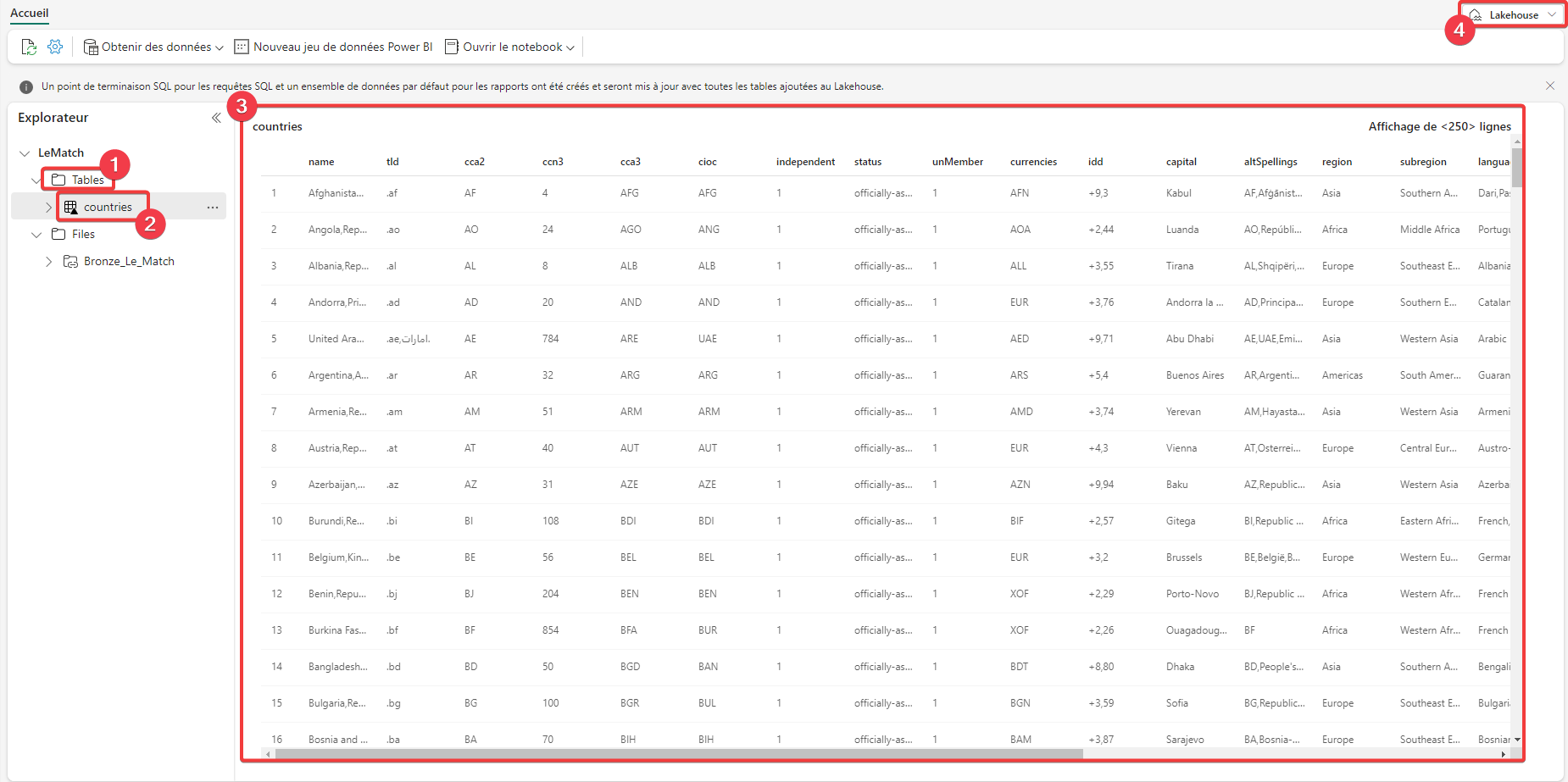
- Sélectionnez les tables du lakehouse.
- Sélectionnez la table countries.
- Vous pouvez voir un aperçu du contenu.
- Passez en mode point de terminaison SQL pour pouvoir écrire une requête SQL sur la table.
Vous pouvez aussi directement ouvrir le point de terminaison SQL depuis l’espace de travail.
Tâches préparatoires à une transformation de données
Charger les données
Pour charger les données d’une table en SQL on utilise la requête suivante :
|
|
Dans notre cas le nom de schéma est le nom par défaut dbo et le nom de la table est countries, la requête SQL est donc :
|
|
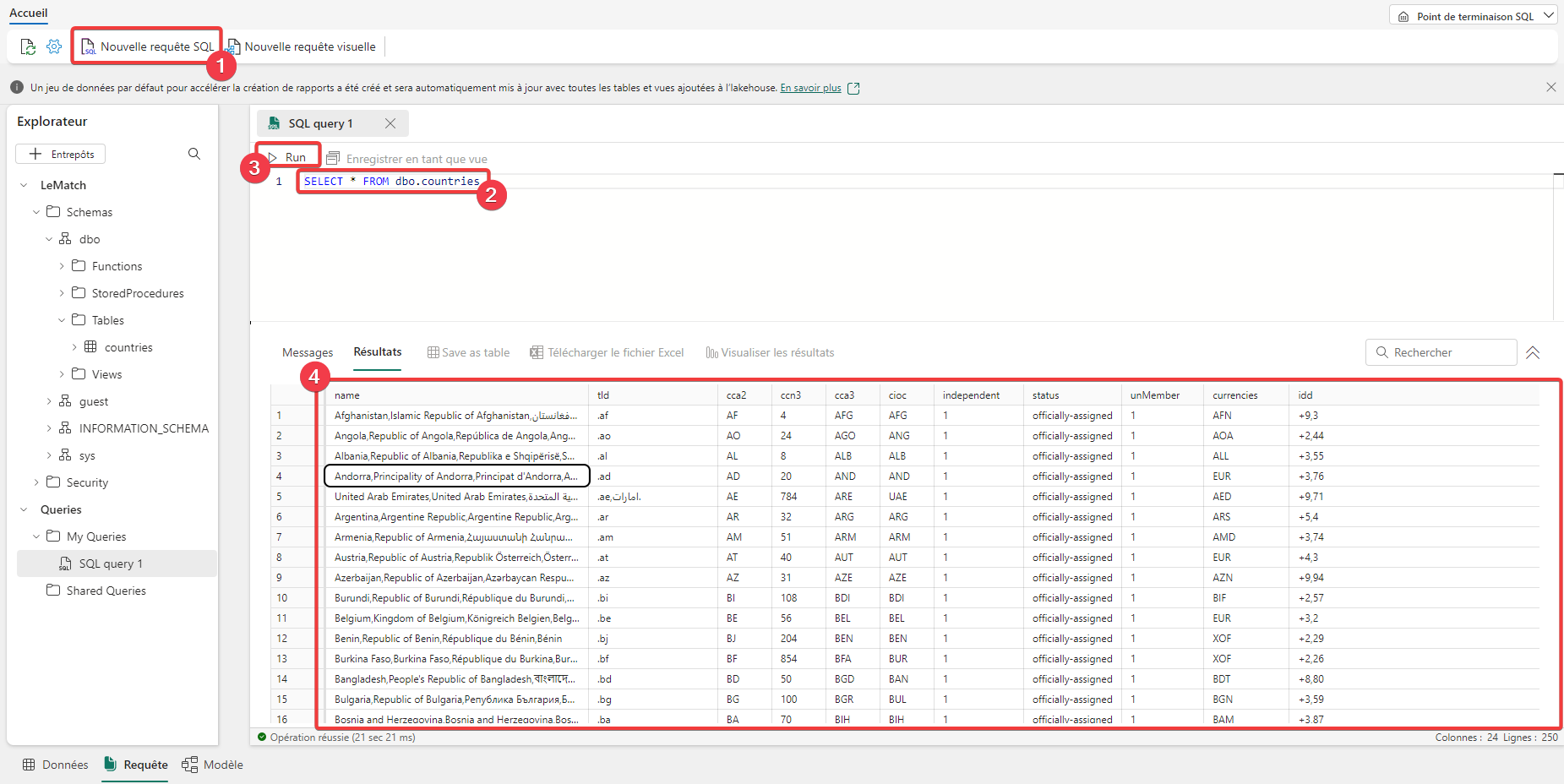
- Dans le point de terminaison SQL, sélectionnez Nouvelle requête SQL.
- Saisir le code de la requête.
- Appuyez sur Run.
- Vous pouvez voir le résultat.
Obtenir un échantillonnage des données
Souvent lire un échantillon des données, les 100 premières lignes par exemple suffit à ce faire une première idée du jeu de données.
En SQL vous pouvez le faire comme cela :
|
|
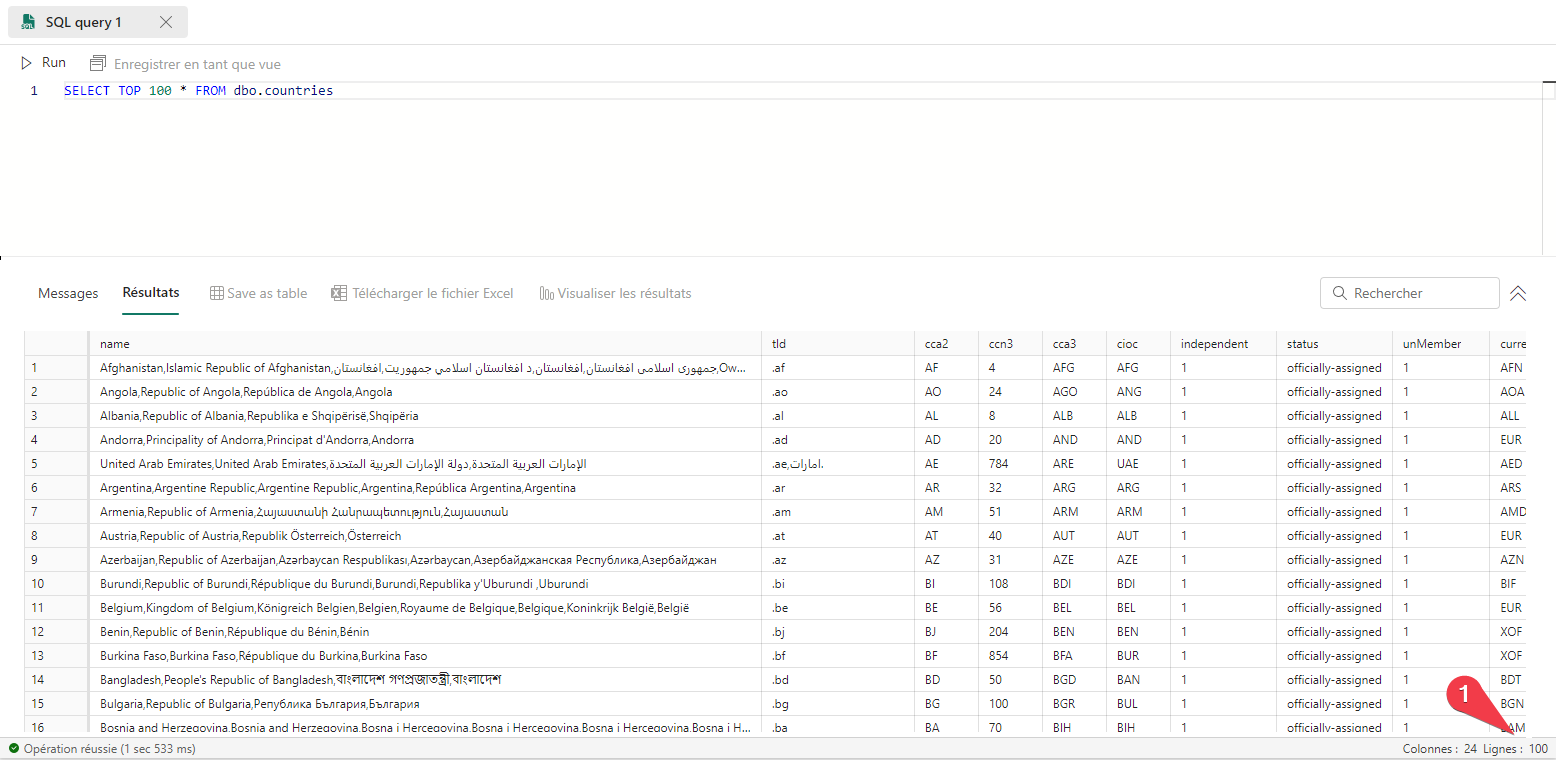
- Vous pouvez constater que l’on a lu que 100 lignes.
Voir les métadonnées du jeu de données
Pour lire les métadonnées de la table, on peut utiliser la requête suivante :
|
|
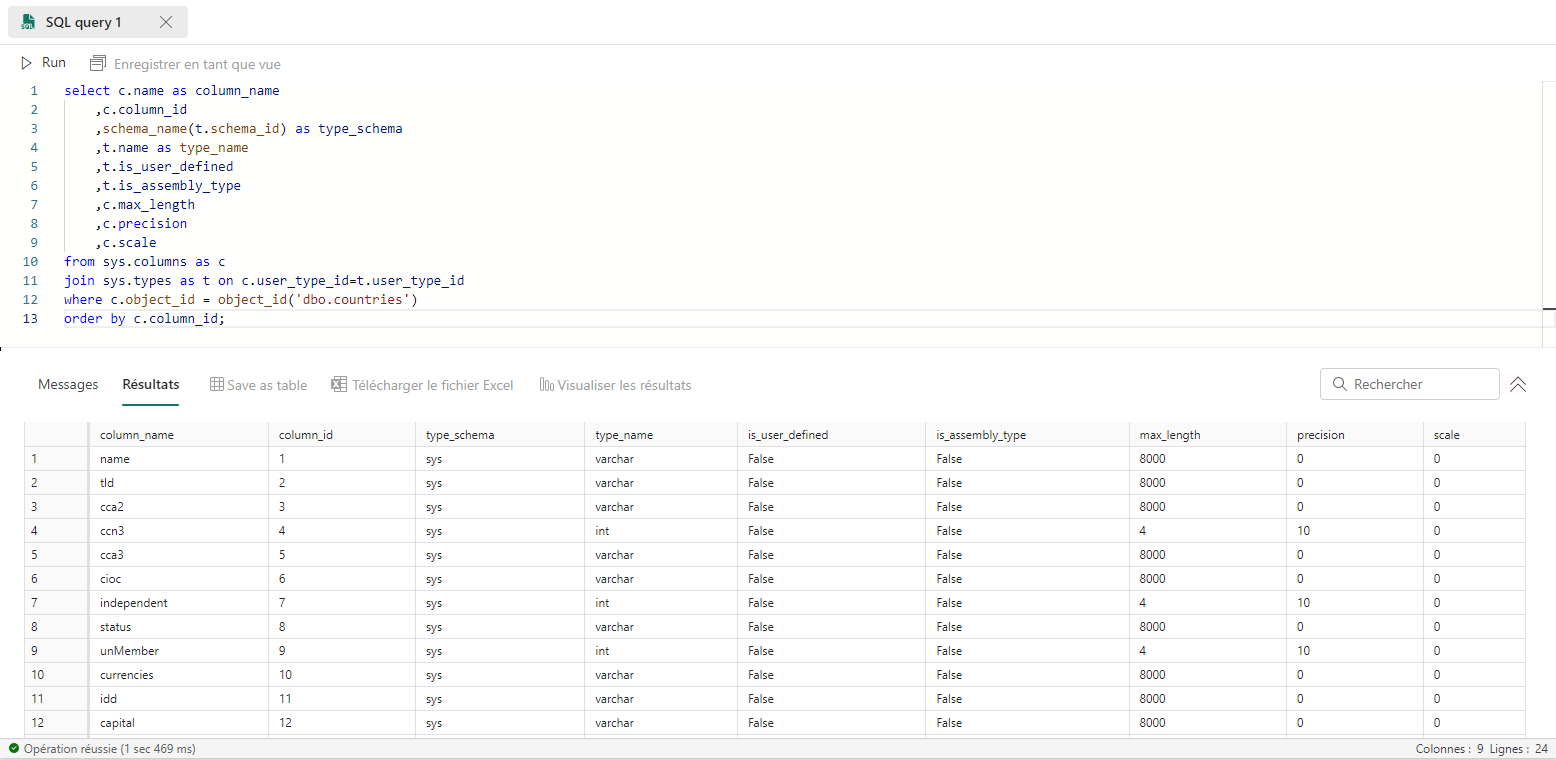
Réaliser les transformations
Sélectionner certaines colonnes
Pour ne sélectionner que les 3 colonnes name, currencies et capital, on utilise la requête suivante :
|
|
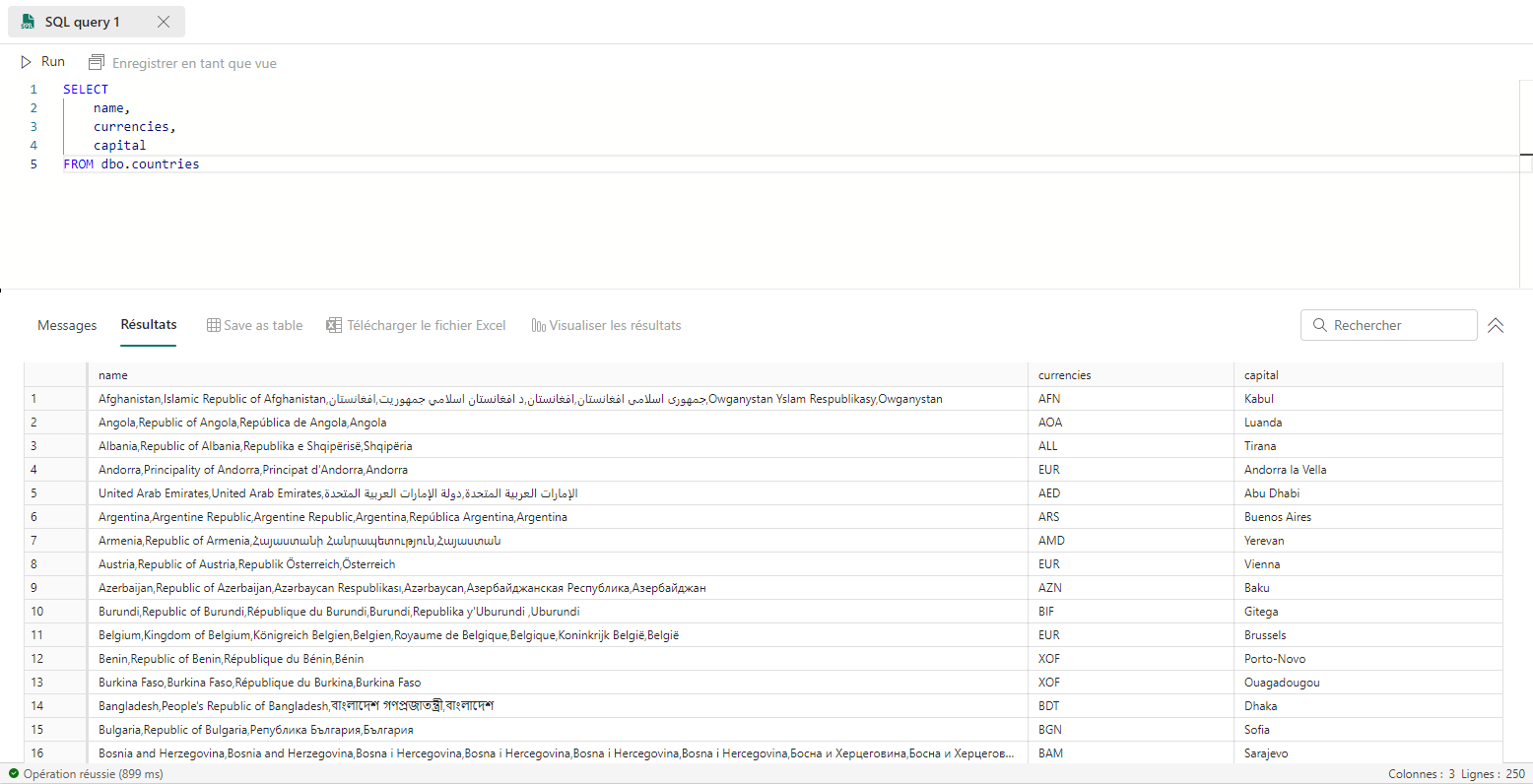
Filtrer les lignes à conserver
Pour ne sélectionner que les lignes ayant pour valeur EUR dans la colonne currencies, on utilise la requête suivante :
|
|
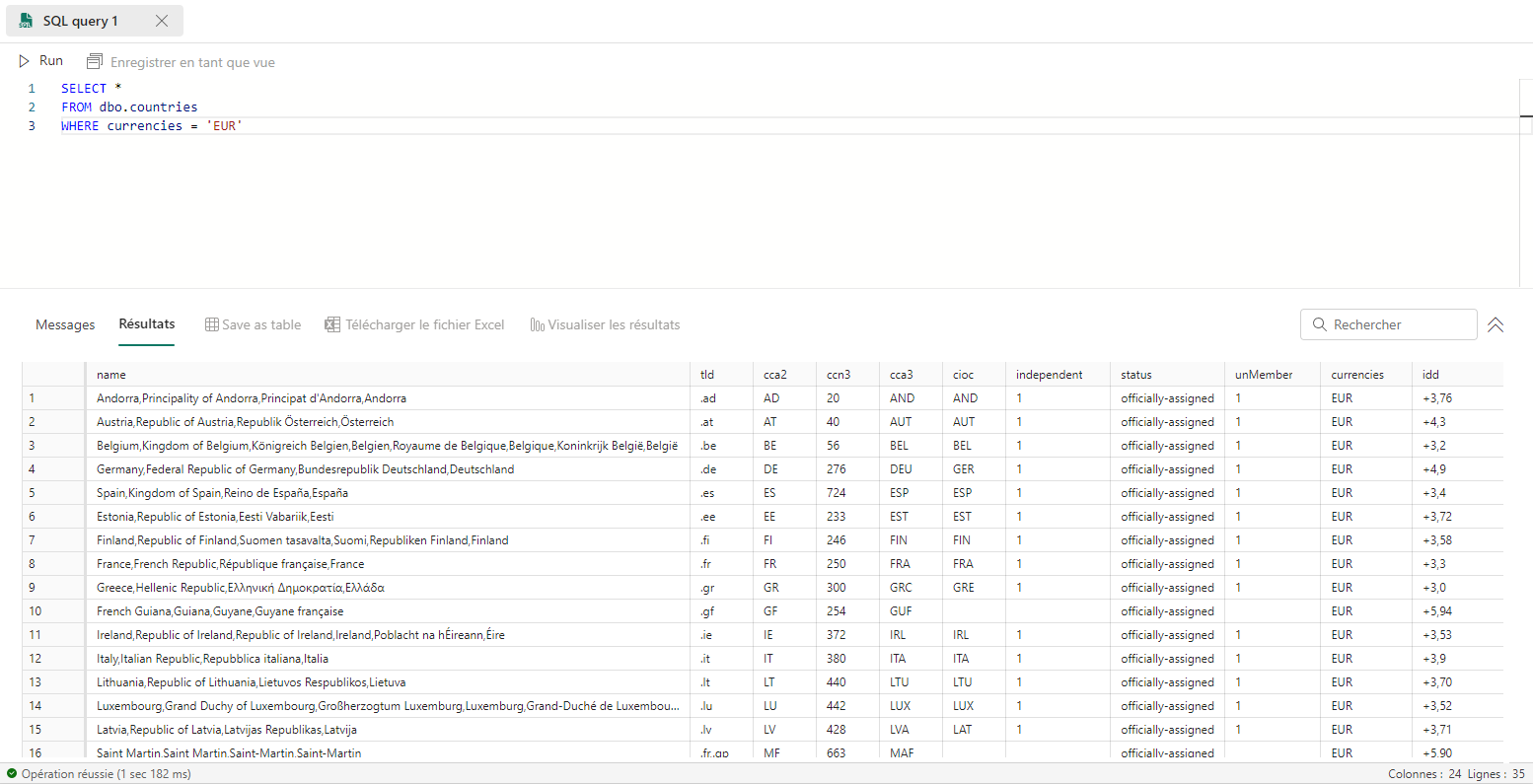
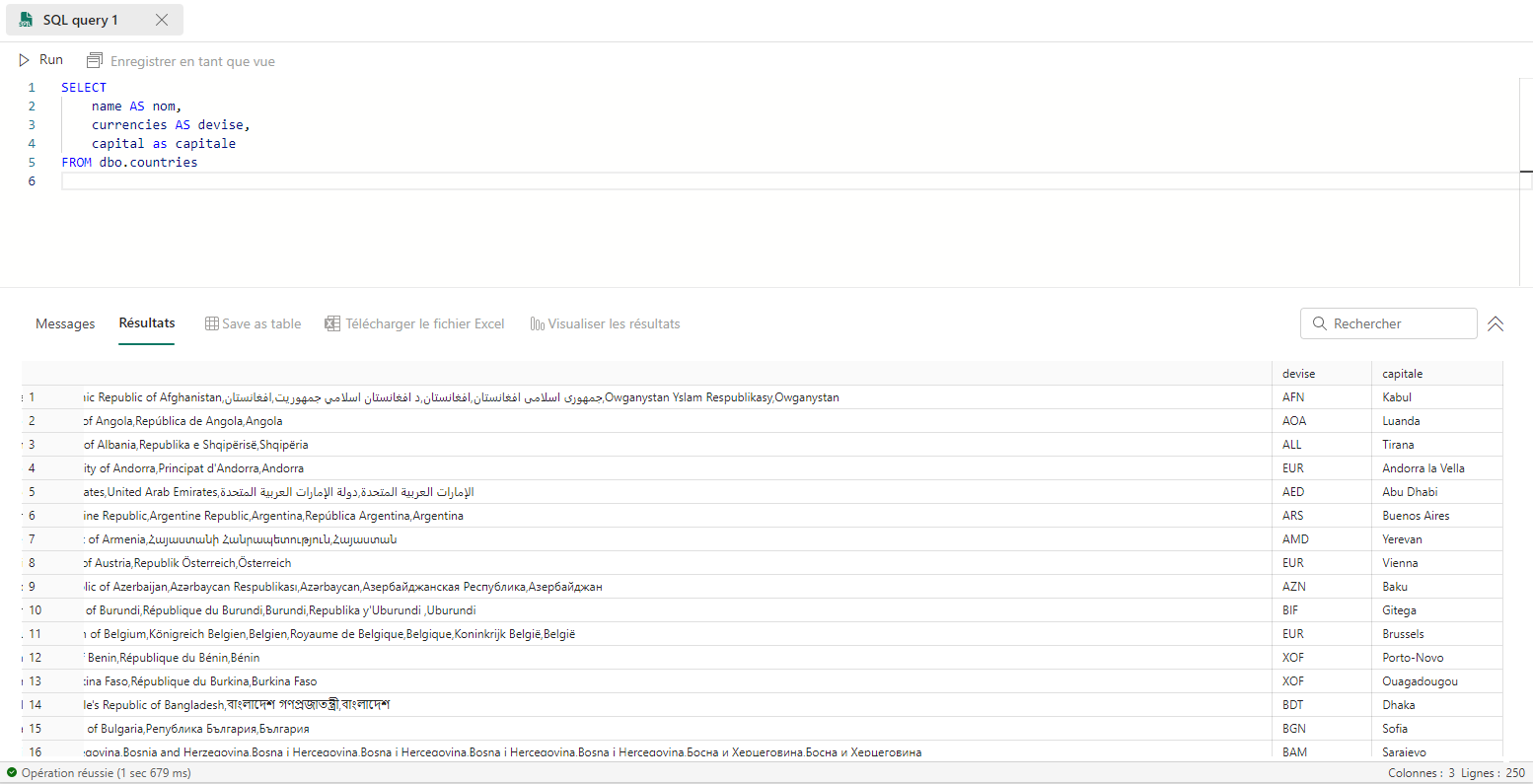
Modifier le nom des colonnes
Pour ne sélectionner que les 3 colonnes name, currencies et capital, et les renommer nom, devise et capitale, on utilise la requête suivante :
|
|
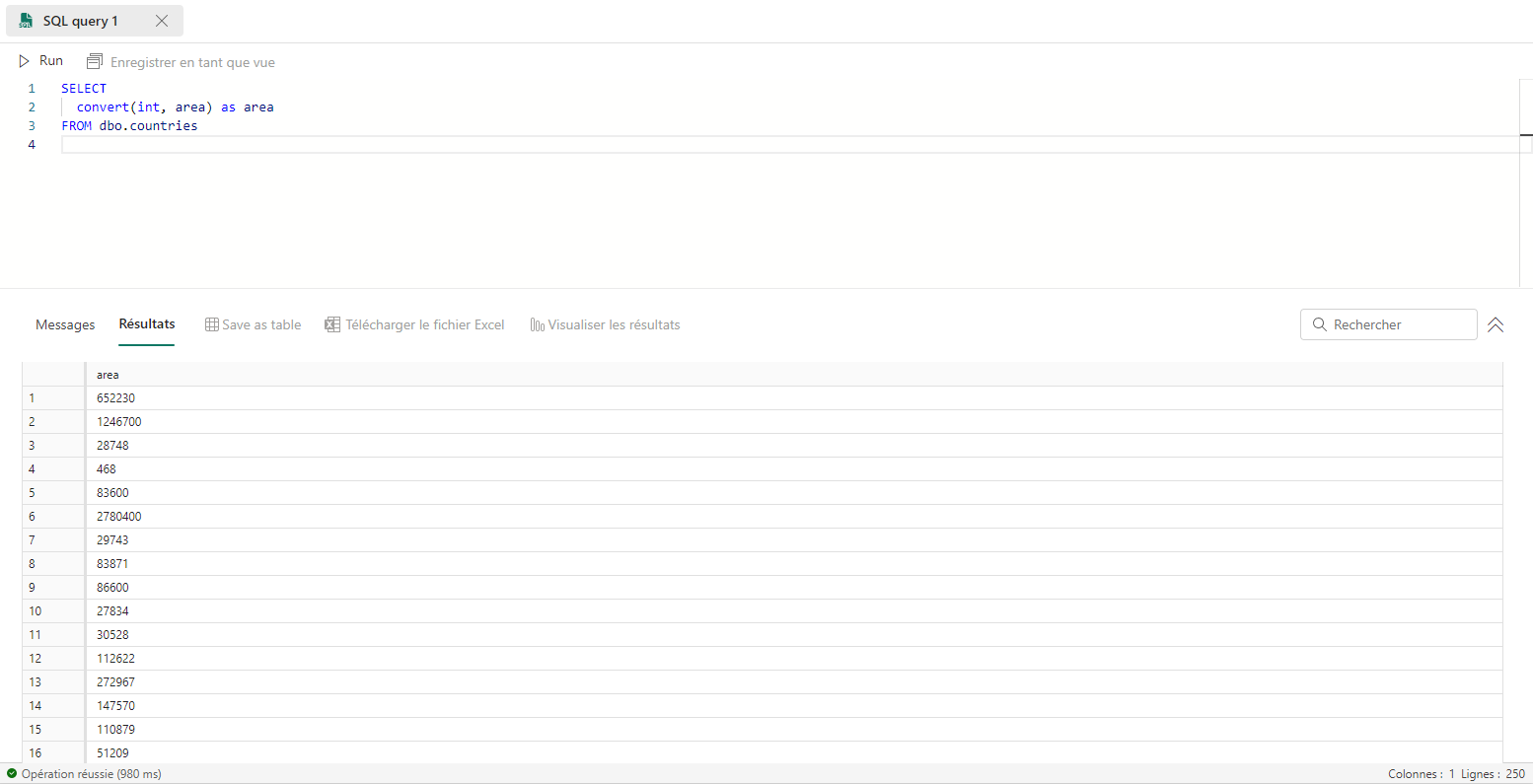
Modifier le type de données des colonnes
Pour convertir la colonne area qui est de type nombre décimal en nombre entier, on utilise la requête suivante :
|
|
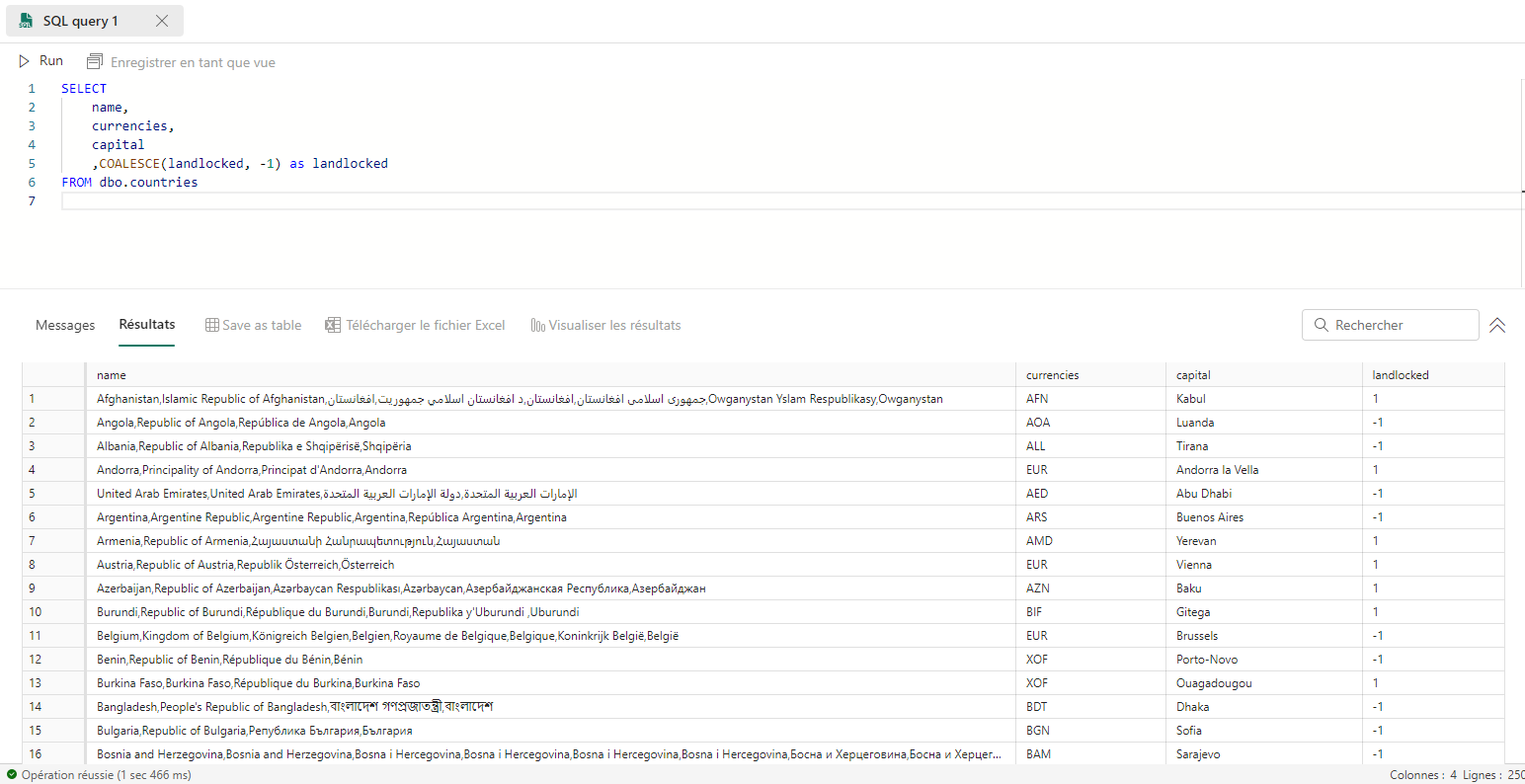
Gestion des valeurs absentes
En SQL les valeurs vides sont appelées valeur null. Pour remplacer les valeurs vides par la valeur -1 de la colonne landlocked et ne conserver en plus que les colonnes name, currencies et capital, on utilise la requête suivante :
|
|
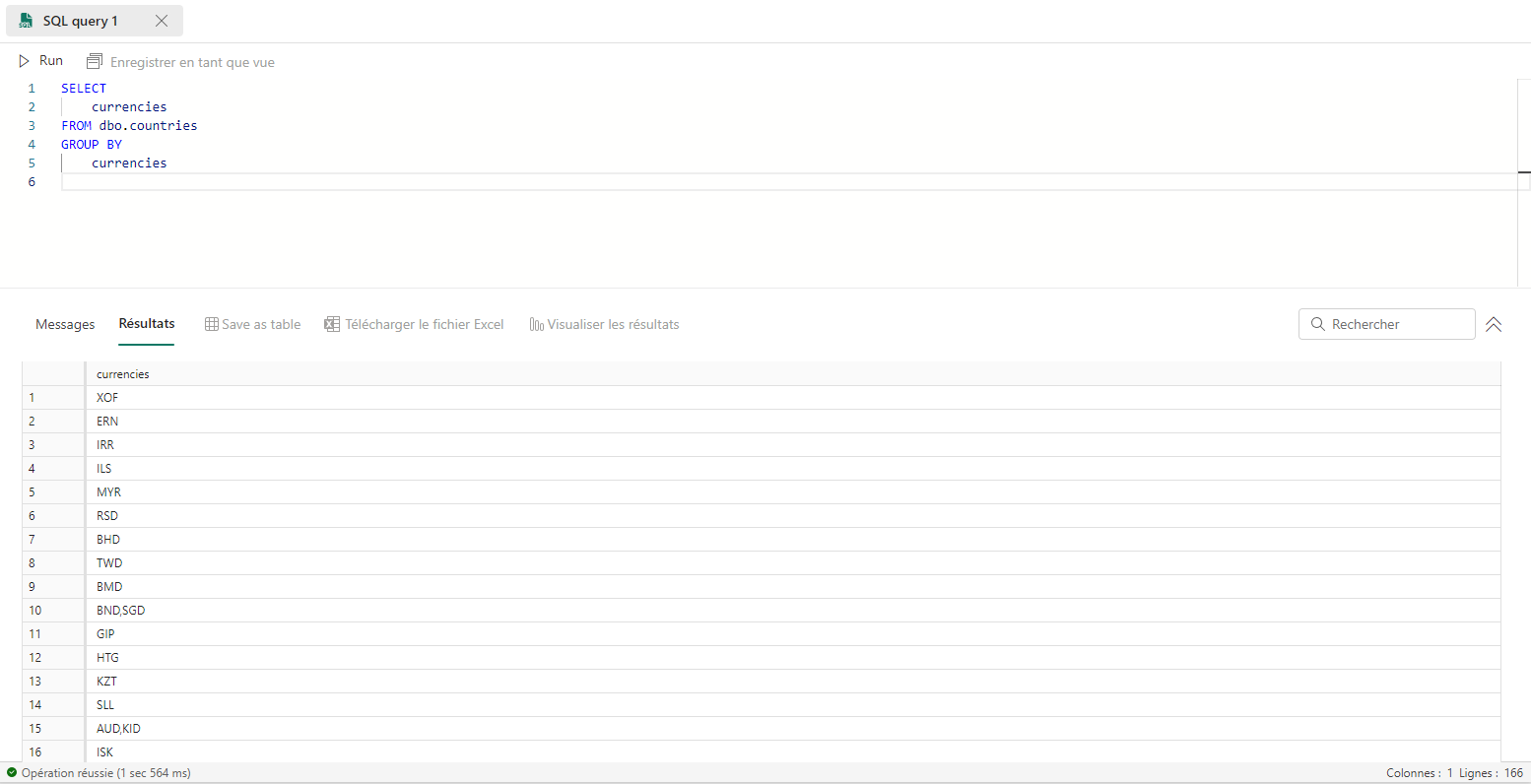
Enlever les doublons
Pour obtenir la liste des devises dédoublonnée, on utilise la requête suivante :
|
|
Sauvegarder le résultat dans la couche Silver
Le résultat que l’on souhaite conserver dans la couche silver est le résultat de la requête suivante :
|
|
Pour copier le résultat de la requête SQL réalisé sur la zone bronse dans la zone silver, nous allons utiliser un pipeline de données.
Vous trouverez un exemple de pipeline de données dans mon article Votre premier pipeline d’intégration de données avec Microsoft Fabric.
Le magasin de données de type lakehouse ne gère, dans la preview, que les tables et les fichiers. Il n’est pas possible d’exécuter une requête SQL, pour résoudre ce problème j’ai créé un warehouse dans l’espace de travail nommé MatchSQL. Le warehouse est un moteur de base de données avec plus de fonctionnalités. Il peut notamment exécuter des requêtes sur les tables du lakehouse dans l’activité de copie du pipeline. Pour cela, il suffit d’ajouter le nom du lakehouse dans la requête SQL. Si aucun nom n’est indiqué c’est l’endroit ù on est connecté qui est utilisé.
La requête SQL devient donc :
|
|
Je créer donc un pipeline dans l’espace de travail Fabric - Le match [Silver].
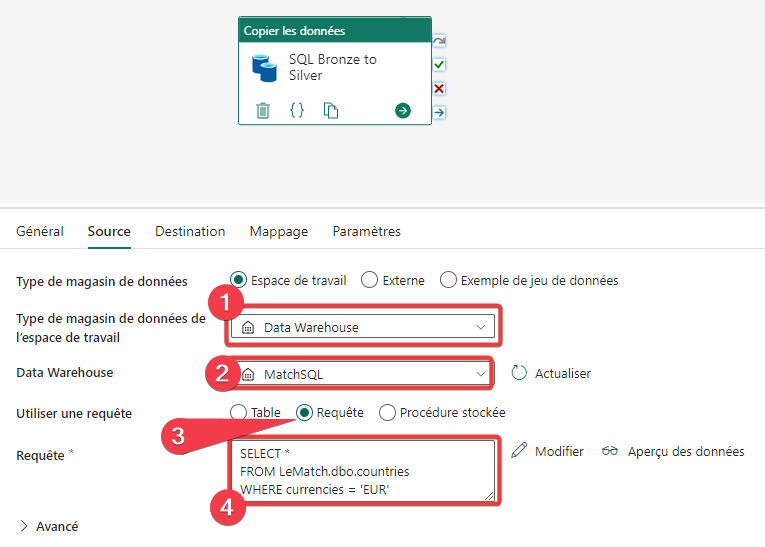
- Sélectionnez Data warehouse comme magasin de données.
- Sélectionnez le warehouse.
- Indiquez que vous allez utiliser une requête.
- Entrez le code SQL de la requête.
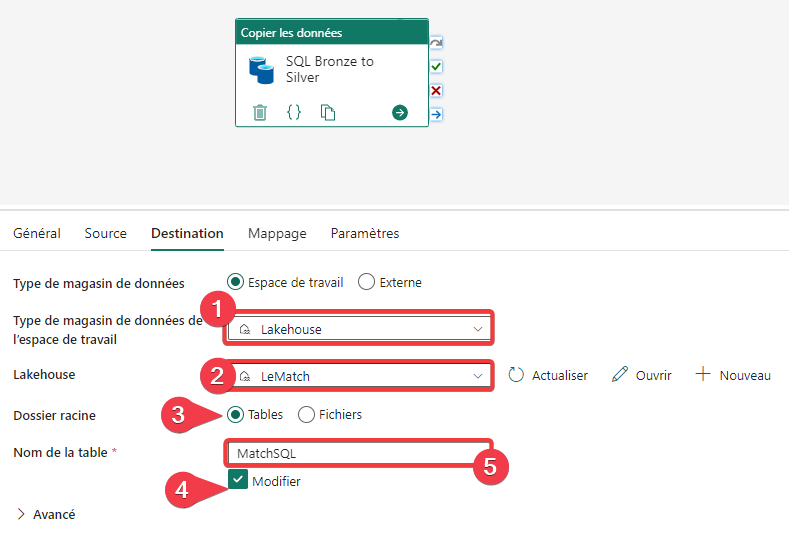
- Sélectionnez Lakehouse comme magasin de données.
- Sélectionnez le lakehouse.
- Indiquez que vous allez utiliser une table comme destination.
- Cochez Modifier pour saisir librement le nom de la table.
- Saisir le nom de la table destination.
Enregistrez et exécutez le pipeline de données, puis rendez-vous dans le lakehouse de l’espace de travail Fabric - Le match [Silver].
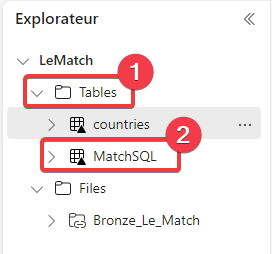
- Dans l’explorateur du lakehouse ouvrez Tables
- Votre nouvelle table est bien créée.
Merci de votre attention.