
On termine le match avec les blocs-notes.
Contexte
Afin de découvrir les différents types de traitement proposé par Microsoft Fabric, je vous ai proposé un match entre 3 différentes possibilités : Préparation de données avec Microsoft Fabric, le match !.
Je me propose ici de réaliser les transformations avec un bloc-notes.
Pour rappel, les blocs-notes permettent d’écrire des séquences de code alterné avec des séquences de texte au format markdown.
Le code est exécuté par un moteur Spark, mais dans l’écosystème de Fabric vous n’y avez pas accès.
Les langages supportés sont :
- Python
- Spark SQL
- Scala
- R
Pour ce match, j’ai choisi d’utiliser le langage Python avec la bibliothèque Pandas 🐼.
Création de notre bloc-notes
Rendez-vous dans l’espace de travail Fabric - Le match [Silver] créer dans l’article de préparation du match.
Ouvrez le lakehouse LeMatch.
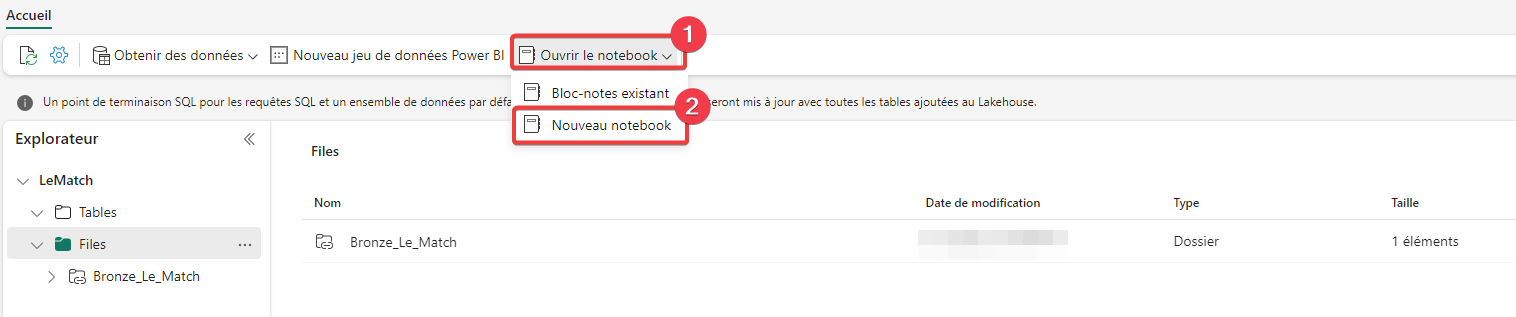
- Dans le menu sélectionnez Ouvrir le notebook.
- Sélectionnez Nouveau notebook.
Le bloc-notes s’ouvre :
Tâches préparatoires à une transformation de données
Charger les données
Pour charger les données, on va utiliser un assistant pour écrire le premier bloc de code.
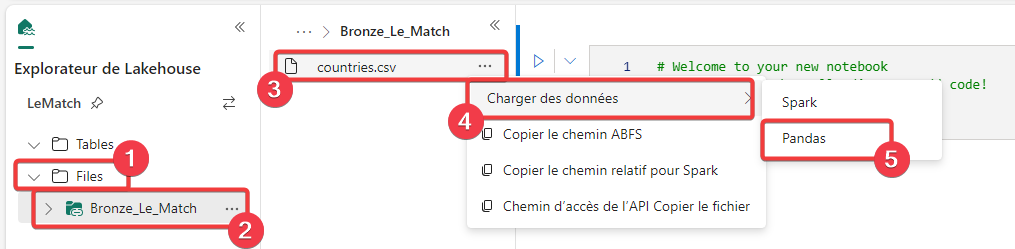
- Ouvrez le dossier Files.
- Sélectionnez le raccourci Bronze_Le_Match.
- Sur le fichier countries.csv appuyez sur les 3 points.
- Sélectionnez Charger des données.
- Sélectionnez Pandas.
Le code suivant est ajouté dans le bloc-notes :
|
|
Explication rapide du code :
- On demande à importer la librairie pandas pour pouvoir l’utiliser.
- On a un commentaire
- On charge dans la variable df le contenu du fichier csv.
- On affiche le contenu de la variable df.
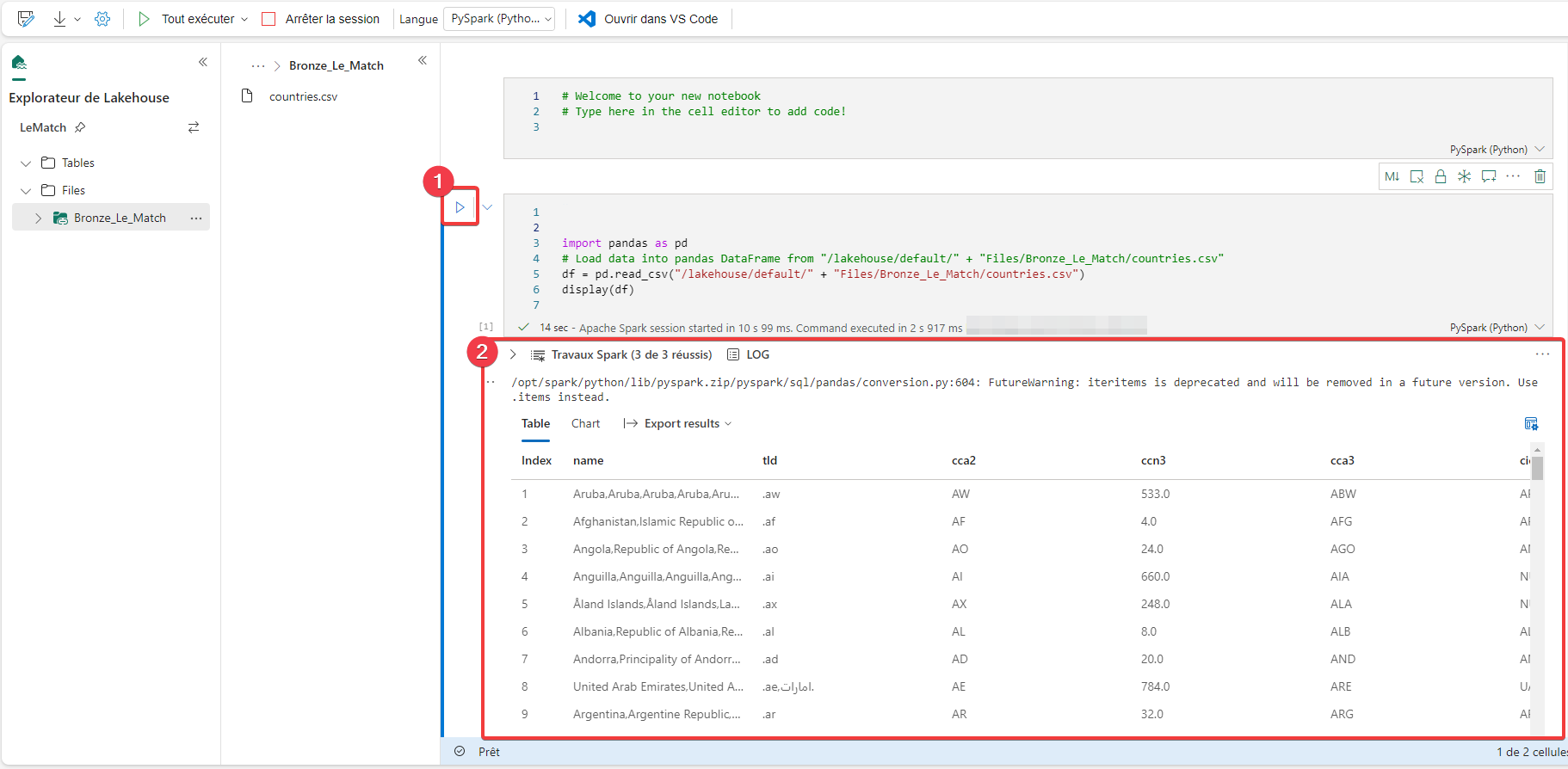
- Pour exécuter le code, appuyez sur l’icône Run cell.
- Vous pouvez voir le résultat directement dans le bloc-notes.
La variable df est utilisable dans les cellules suivantes du notebook.
Si vous avez un message d’erreur vous disant que df n’est pas défini, le serveur a probablement réinitialisé votre session. Il suffit de relancer le code de chargement de données pour continuer.
Obtenir un échantillonnage des données
Pour ne voir que les 10 premières lignes du jeu de données, on utilise le code suivant :
|
|
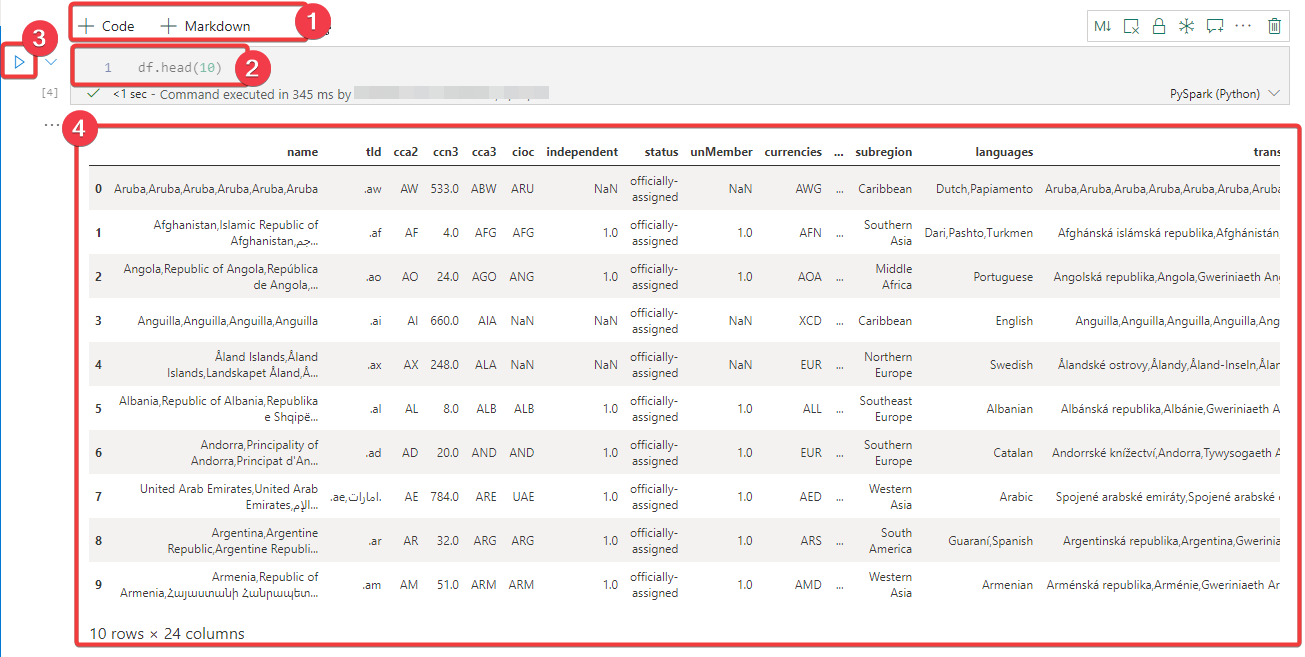
- Appuyez sur + Code pour ajouter une nouvelle cellule dans le bloc-notes.
- Saisir le code.
- Exécuter le code, appuyez sur l’icône Run cell.
- Vous pouvez voir le résultat directement dans le bloc-notes.
Pour la suite je ne vous montrerais que le résultat du code, la procédure d’ajout et d’exécution étant toujours la même.
Voir les métadonnées du jeu de données
Pour voir les métadonnées, on utilise le code suivant :
|
|
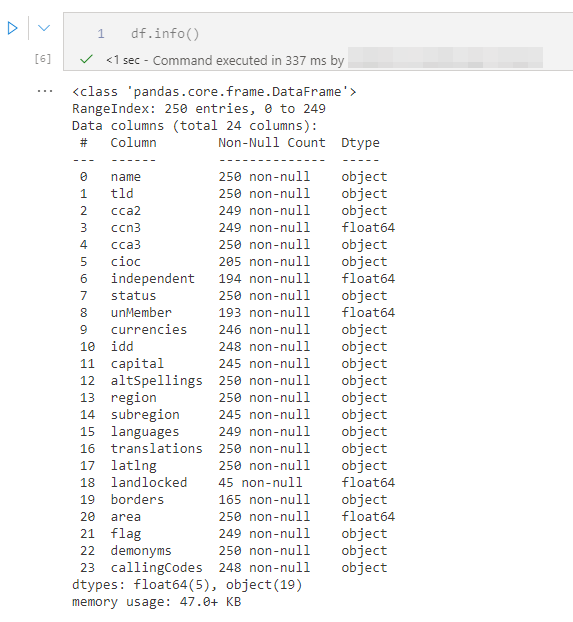
Réaliser les transformations
Sélectionner certaines colonnes
Pour ne sélectionner que les 3 colonnes name, currencies et capital, on utilise le code suivant :
|
|
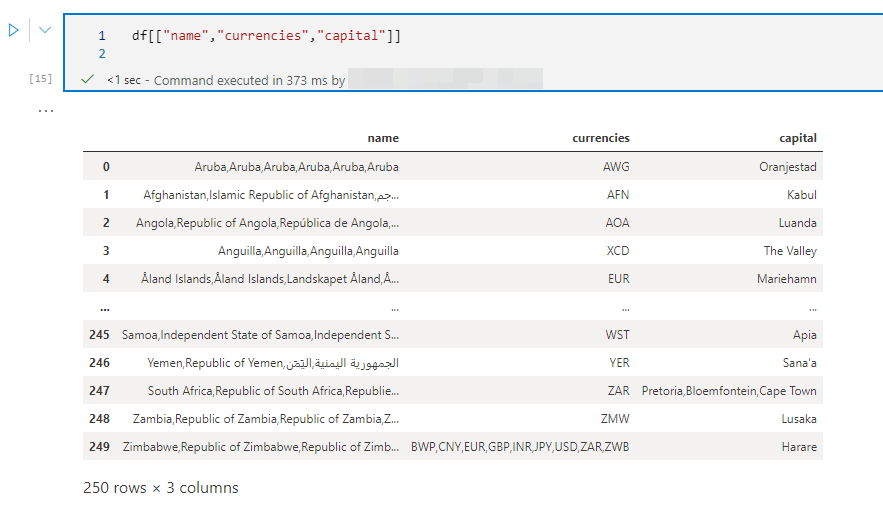
Le jeu de données df est modifié, recharger le avec la commande de chargement de données pour la suite des exemples.
Filtrer les lignes à conserver
Pour ne sélectionner que les lignes ayant pour valeur EUR dans la colonne currencies, on utilise le code suivant :
|
|
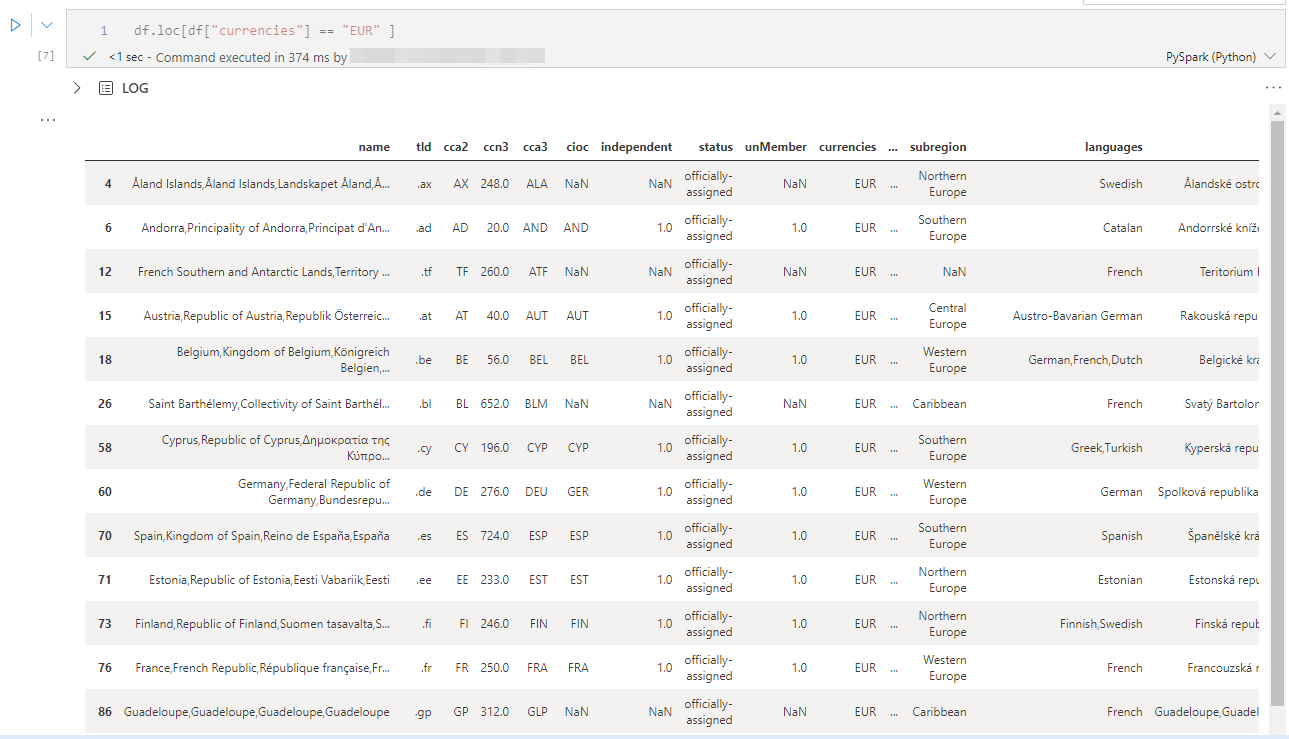
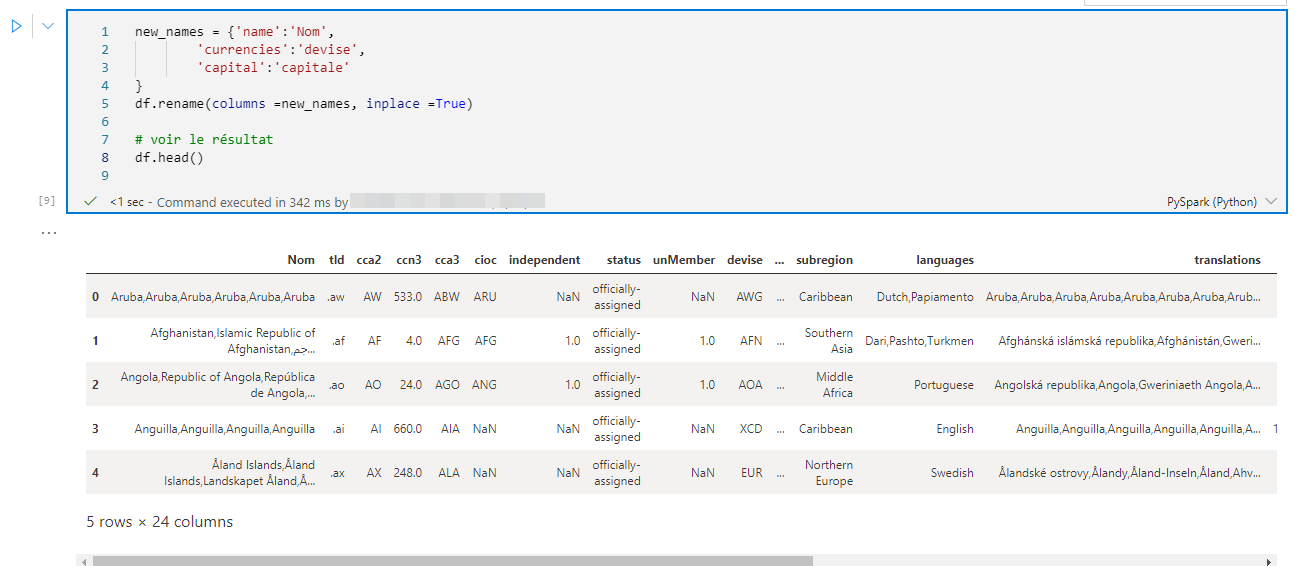
Modifier le nom des colonnes
Pour renommer que les 3 colonnes name, currencies et capital, en nom, devise et capitale, on utilise le code suivant :
|
|
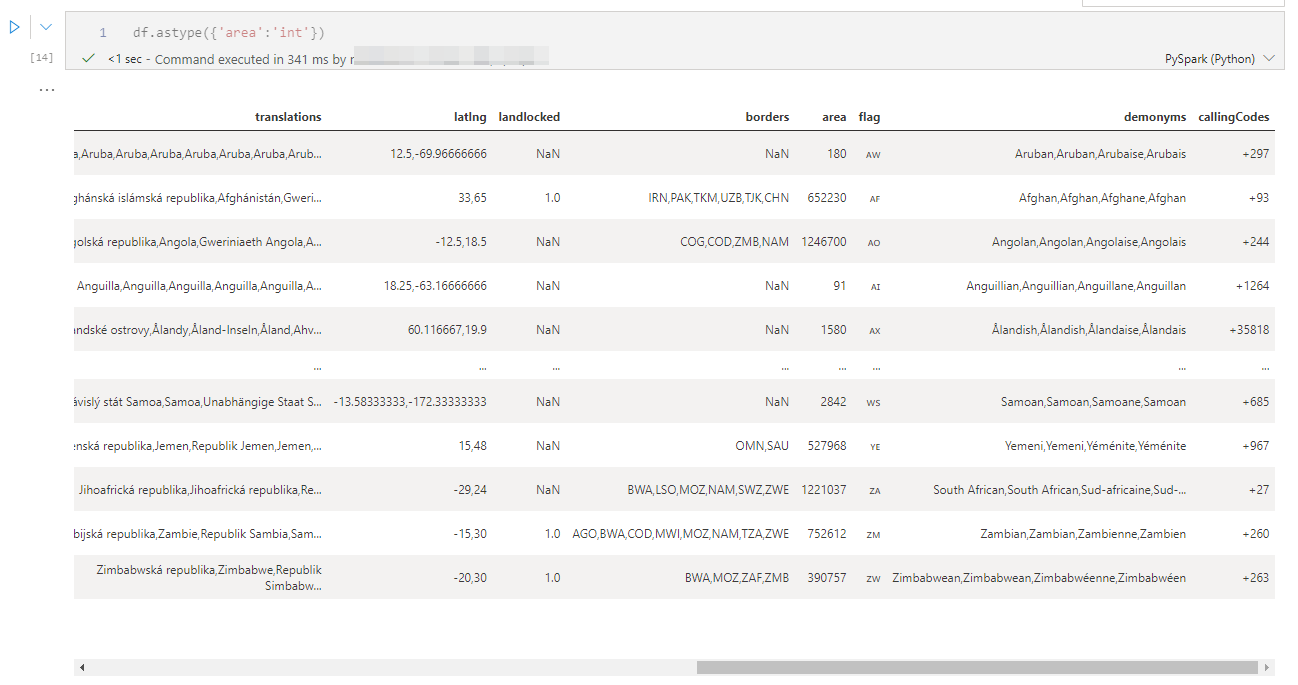
Modifier le type de données des colonnes
Pour convertir la colonne area qui est de type nombre décimal en nombre entier, on utilise le code suivant :
|
|
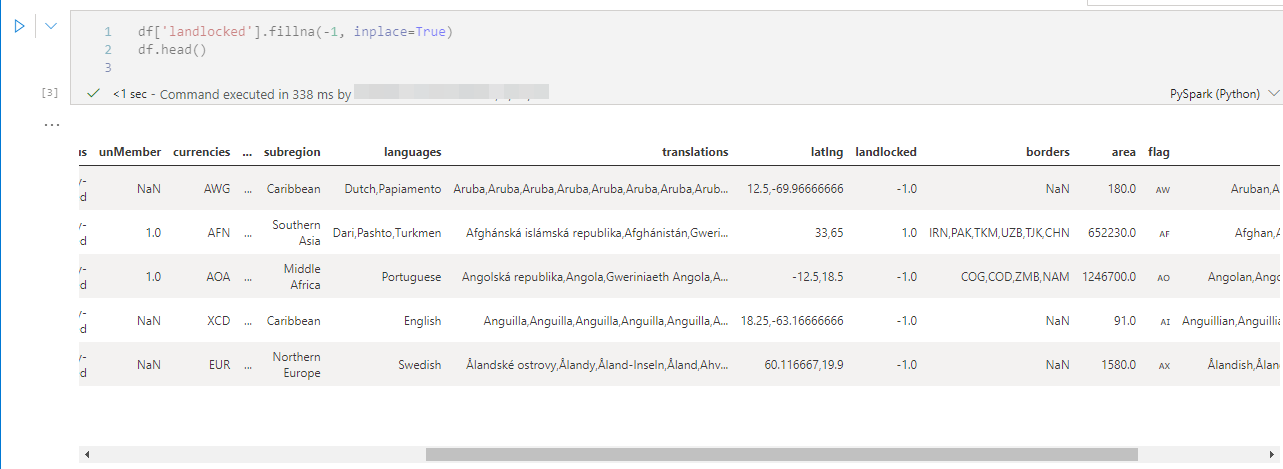
Gestion des valeurs absentes
Pour remplacer les valeurs vides par la valeur -1 de la colonne landlocked, on utilise le code suivant :
|
|
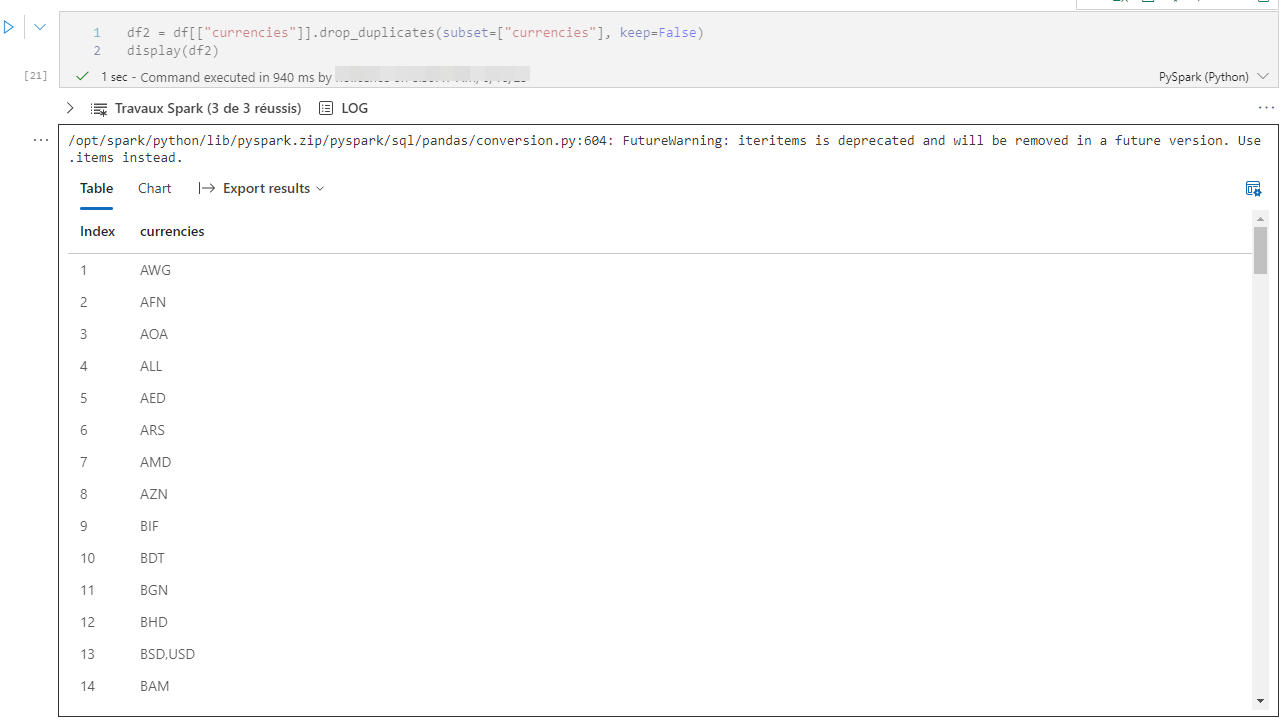
Enlever les doublons
Pour obtenir la liste des devises dédoublonnée, on utilise le code suivant :
|
|
Sauvegarder le résultat dans la couche Silver
Le résultat que l’on souhaite conserver dans la couche silver est le résultat de la variable df2 vers un fichier parquet, tel que le montre le code suivant :
|
|
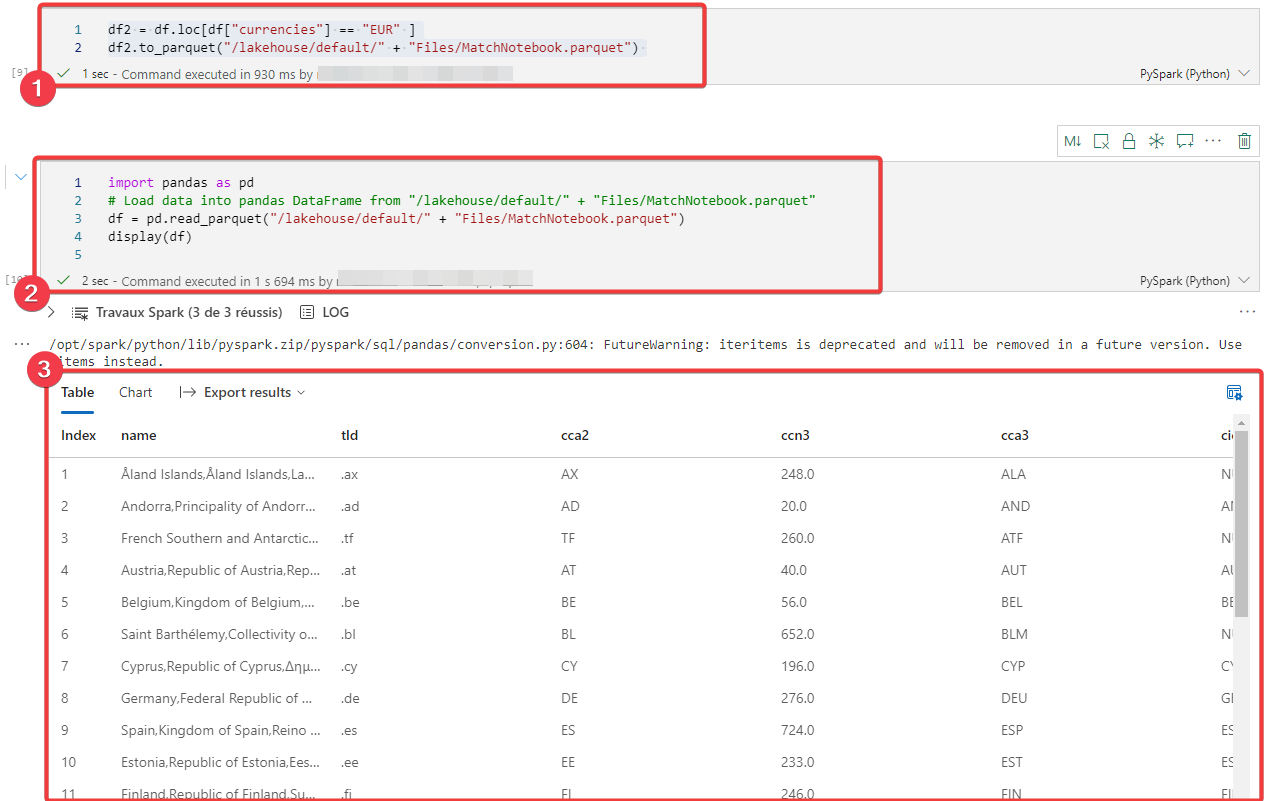
- Exécutez le code ci-dessus pour sauvegarder les données sélectionnées dans un fichier parquet.
- Depuis l’explorateur de lakehouse, localiser votre fichier (pensez à rafraichir si il n’apparait pas) et générer le code pour le lire (comme pour le csv au début).
- Vous pouvez voir le résultat dans la couche silver.
Merci de votre attention.