
Dans cet article je vous propose de tester et de créer une première intégration de données avec un pipeline de Microsoft Fabric.
Contexte
Dans cet article je vous propose de suivre toutes les étapes de création d’un flux d’intégration de données.
Pour réaliser cette tâche, nous allons utiliser le pipeline de données. Un pipeline permet de facilement faire de la copie de données entre 2 points et d’ordonnancer toute sorte de tâches afin de créer des traitements de données robustes et cohérents.
Architecture médaillon
Nous allons nous inspirez de l’architecture médaillon, pour simplifier nous allons avoir 3 zones dans lesquelles vont résider nos données :
- La zone bronze 🥉 : Elle contient les données brutes historiques, non traitées.
- La zone silver 🥈 : Elle contient les données préparer, valider et prête à l’usage.
- La zone gold 🥇 : Elle contient les données affinées et agrégées utilisables directement notamment par les outils analytiques.
Lors du passage d’une zone à une autre, les données de la zone précédente sont conservées en l’état. Nous avons donc plusieurs copies de la même donnée dans des états différents.
Préparer votre environnement de travail
Je vous propose de réaliser un exemple d’intégration de données externe, via une source de données de type OData public vers la couche bronze 🥉.
Nous allons maintenant préparer un environnement pour recevoir les données.
Création d’un espace de travail gérant les objets Fabric
Rendez-vous sur le portail Power BI, Fabric doit être activé dans votre environnement, si ce n’est pas le cas, suivez ce tutoriel : Version d’évaluation de Microsoft Fabric.
Dans le menu de gauche, sélectionnez Espace de travail, puis + Nouvel espace de travail.
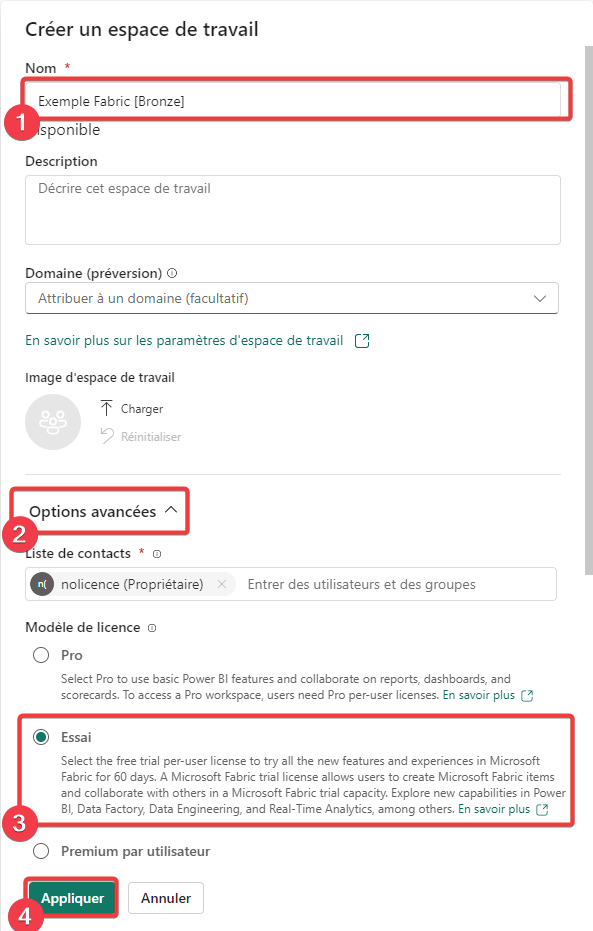
- Donnez un nom à votre espace de travail
- Ouvrez les options avancées
- Sélectionnez un type d’espace de travail compatible avec les objets Micrsoft Fabric.
- Appuyez sur Appliquez pour créer votre espace de travail.
Sélection de l’expérience utilisateur
Afin de simplifier l’interface, Fabric est organisé autour de différentes expériences utilisateur afin de ne pas présenter l’ensemble des types objets disponible à tout le monde. Pour notre exemple nous pouvons utiliser l’expérience Data Factory ou Engineering données.

- Appuyez sur l’icône en bas à gauche de votre écran, si vous êtes arrivé par le portail Power BI vous trouver l’icône Power BI, sinon vous trouverez l’icône de l’expérience utilisateur en cours.
- Sélectionnez Data Factory
Après le changement d’expérience, vous devez vous repositionner dans votre espace de travail.
Création d’un DatalakeHouse
Nous allons maintenant créer un Lakehouse dédié à notre exemple.
Un lakehouse est une espace de stockage acceptant n’importe quel type de données. Il sert de zone de stockage générique des données de notre couche bronze.
Dans l’écosystème Fabric un lakehouse est un sous-ensemble de OneLake, l’espace de stockage unifié de votre entreprise.
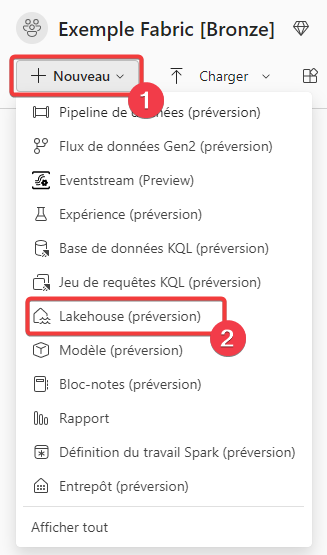
- Dans le menu de l’espace de travail, appuyez sur + Nouveau.
- Sélectionnez Lakehouse.
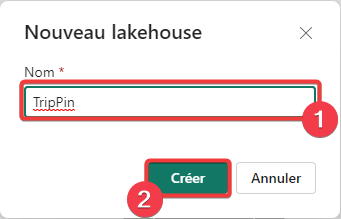
- Saisissez le nom du lakehouse, ici TripPin qui est le nom de la source de données.
- Appuyez sur Créer pour créer le lakehouse.
L’écran qui s’affiche est l’explorateur de lakehouse.
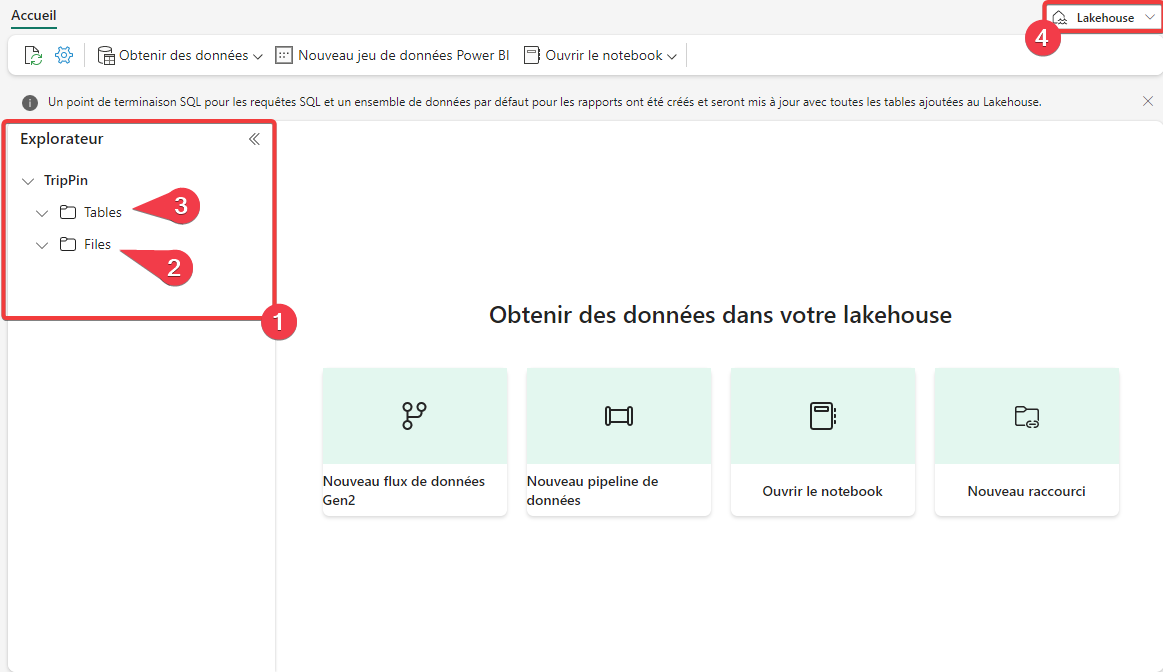
- Dans l’explorateur de lakehouse, vous pouvez naviguer dans les dossiers.
- La section Files permet d’avoir la vision des fichiers bruts stockés dans le lakehouse, on parle de données non managées.
- La section Tables permet d’avoir la vision base de données des fichiers dans le lakehouse et de pouvoir les requêter avec le langage SQL, on parle de données managées.
- Vous pouvez passer de la vue lakehouse à la vue point de terminaison SQL ici.
Pour chaque lakehouse, un point de terminaison SQL est automatiquement créé, ce dernier permet de créer des requêtes de SQL de type SELECT uniquement sur vos fichiers de données. Vous pouvez aussi faire de jointure SQL entre 2 tables ou plus présente dans le lakehouse.
Retournez au niveau de l’espace de travail.
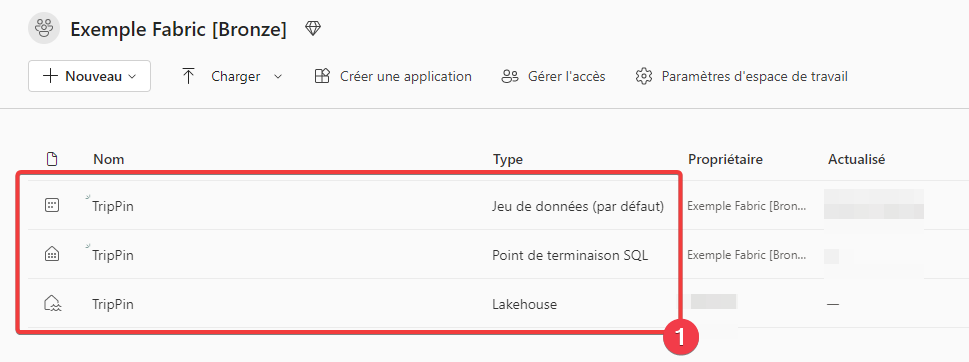
- Vous pouvez constater que 2 objets on était automatiquement créer avec votre lakehouse
- Le point de terminaison SQL comme vue ci-dessus.
- Un jeu de données par défaut pour Power BI. Ce jeu de données est managé par Fabric.
Créer un pipeline
Maintenant que notre environnement de travail est prêt, nous allons pouvoir créer notre traitement d’intégration de données, pour cela nous allons choisir un pipeline de données.
Les pipelines de données présents dans Microsoft Fabric, sont une évolution des pipelines que l’on trouve dans les services Azure Data factory et Azure Synapse Analytics.
En termes d’interface utilisateur et de possibilité, ils sont très proches de ces derniers, mais ils ont subi une très forte simplification. Par exemple, la notion de service lié et de jeu de données n’existe plus dans Fabric elle est remplacée par les connexions. On constate aussi que seules les principales activités de pipeline reste présentent dans Fabric.
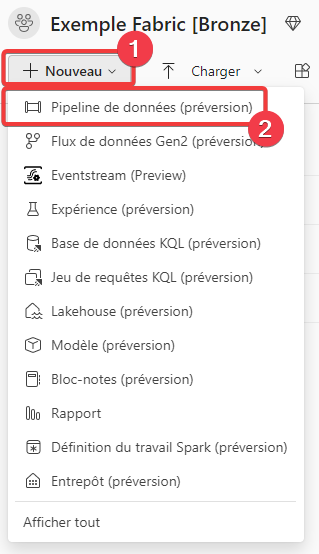
- Dans le menu de l’espace de travail, appuyez sur + Nouveau.
- Sélectionnez Pipeline de données.
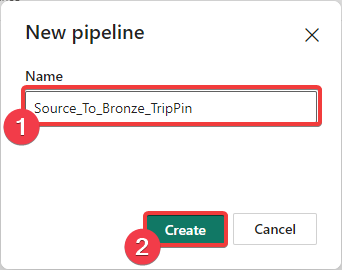
- Saisissez le nom du pipeline, ici Source_To_Bronze_TripPin qui est le nom de la source de données.
- Appuyez sur Créer pour créer le pipeline.
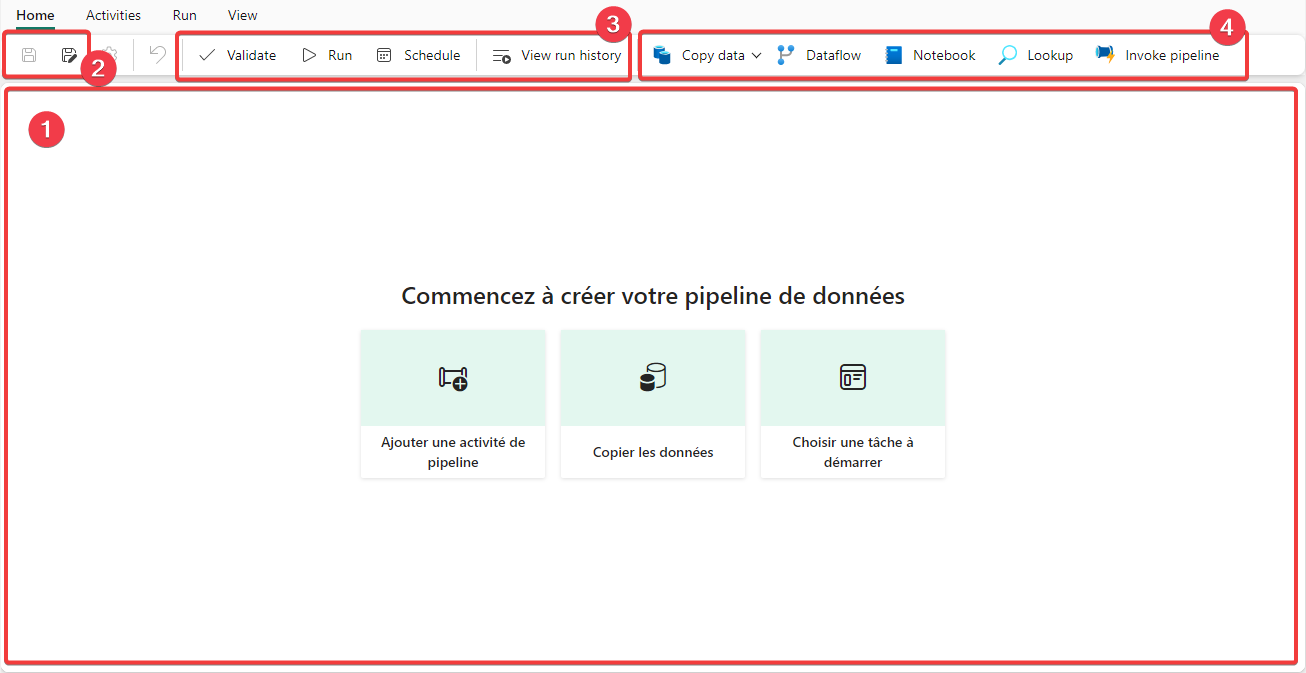
- On retrouve principalement la zone d’édition des activités du pipeline
- Dans le menu Home nous avons les icônes de sauvegarde de notre travail.
- On retrouve les principales fonctions du menu Run.
- Ainsi que les principales activités.
Un pipeline se compose :
- D’activités qui correspondent à des briques permettant de réaliser des actions.
- De connexions permettent de communiquer avec un service de données.
- D’une planification pour automatiser l’exécution du pipeline.
Les connexions
Les connexions permettent de communiquer avec un service de données.
Elles peuvent être créées directement depuis le pipeline, depuis le portail de gestion des passerelles et connexions ou depuis votre espace de travail en ouvrant le menu de la roue crantée en haut à droite puis en sélectionnant Gérer des connexions et des passerelles.
Pour le moment Fabric ne gère que les connexions vers des services Internet, prochainement un accès a vos données d’entreprise sera surement possible via la passerelle Power BI ou un processus équivalent.
Les activités
Les activités sont des composants génériques qui utilisent les connexions pour réaliser des actions standard dessus. Toutes les activités ne peuvent pas utiliser tous les types de connexion.
Les principales activités sont :
- Copy data : permets de réaliser une copie de données entre une source et une destination.
- Dataflow : permets d’exécuter un dataflow.
- Notebook : permets d’exécuter un notebook.
- Loockup : permets d’interroger les données d’une connexion.
- Invoke pipeline : permets d’exécuter un autre pipeline.
Vous retrouverez aussi des activités vous permettant de gérer l’exécution de votre pipeline avec notamment des variables ou des boucles.
Copier une table de données dans notre lakehouse
Nous allons maintenant procéder à la création de notre premier pipeline. Le but de ce pipeline va être de copier les données d’une source OData vers notre lakehouse.
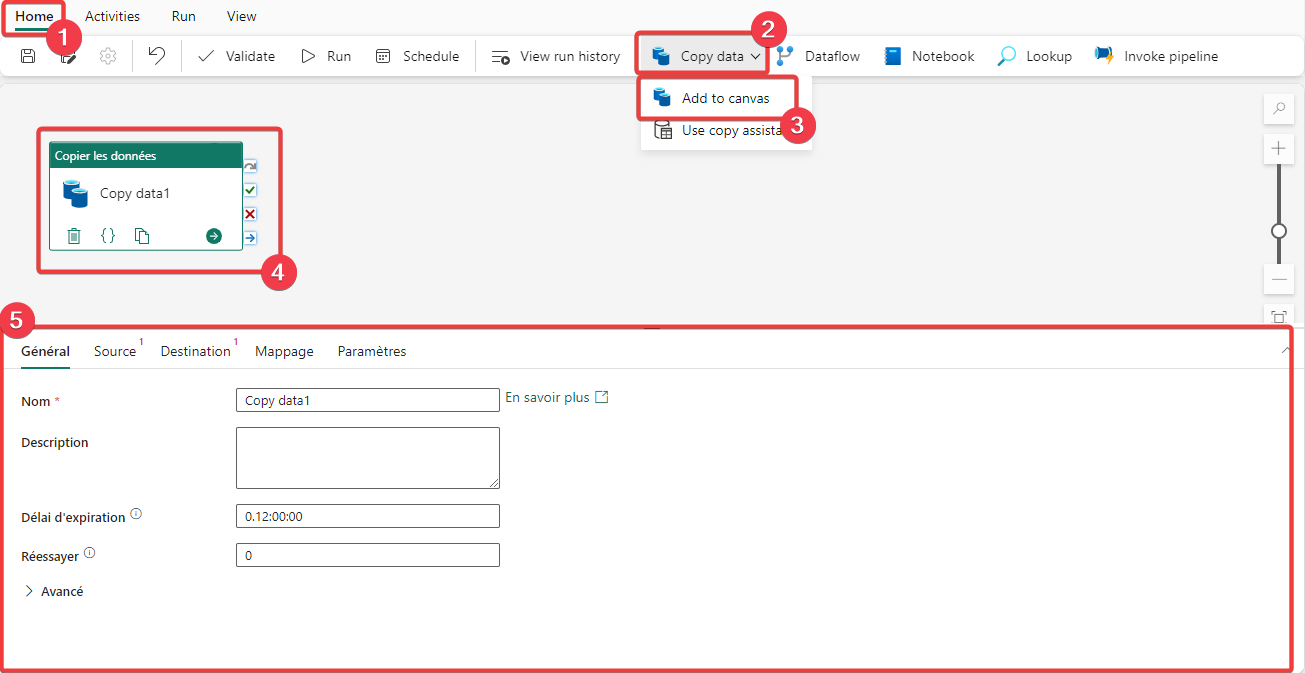
- Dans le menu Home du pipeline.
- Sélectionnez Copy data.
- Cliquez sur Add to canvas.
- L’activité de copie apparait dans la zone d’édition du pipeline.
- Lorsque l’activité de copie est sélectionnée, vous pouvez accéder à ces propriétés.
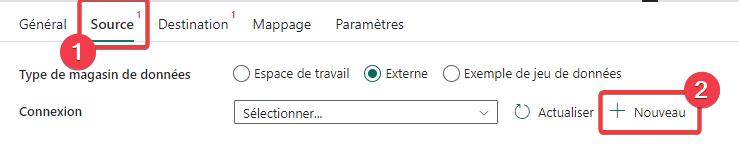
- Dans les propriétés de l’activité de copie, sélectionnez Source.
- Appuyez sur + Nouveau pour créer une nouvelle connexion.
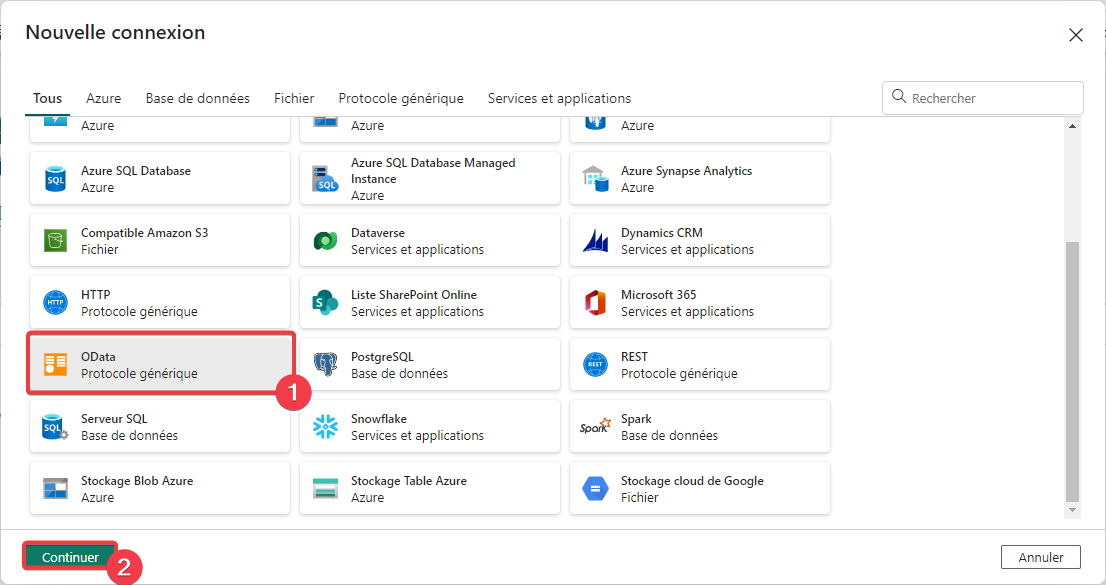
- Sélectionnez le connecteur OData.
- Appuyez sur Continuer.
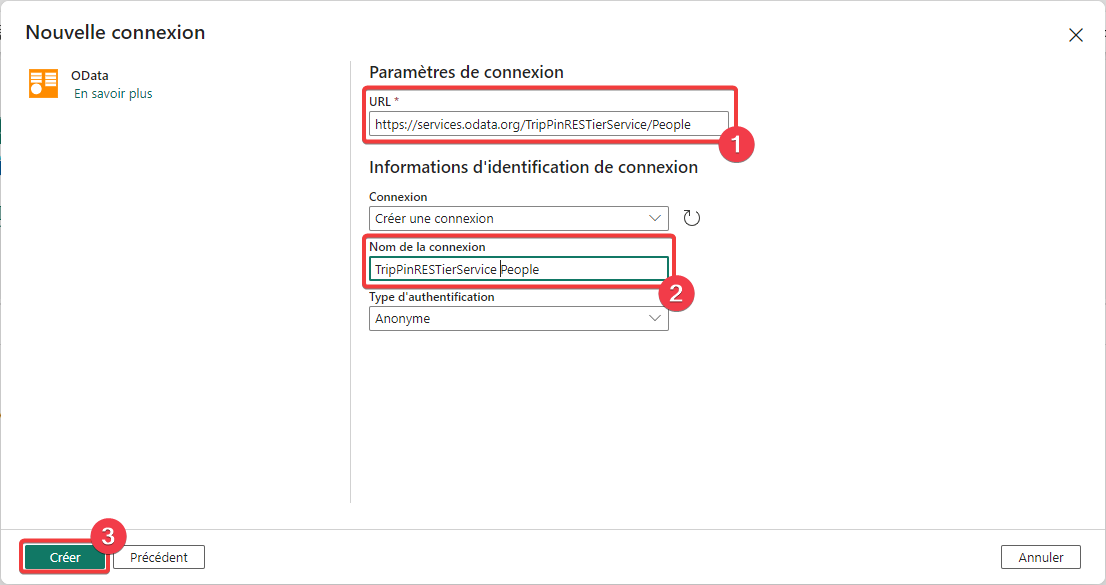
- Dans URL entrez l’adresse https://services.odata.org/TripPinRESTierService.
- Dans Nom de la connexion entrez TripPinRESTierService.
- Appuyez sur Créer pour créer la nouvelle connexion.
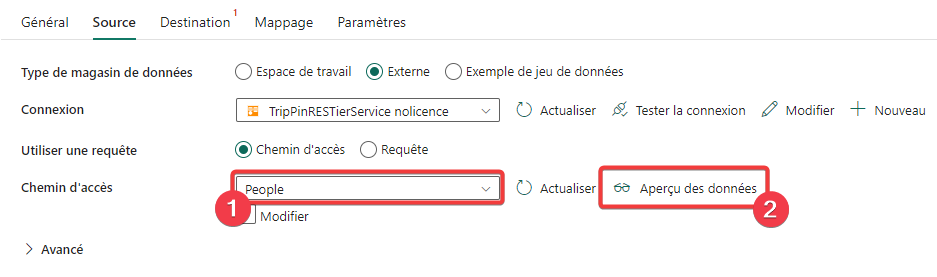
- Dans Chemin d’accès sélectionnez People.
- Appuyez sur Aperçu des données pour tester si vous accédez aux données.
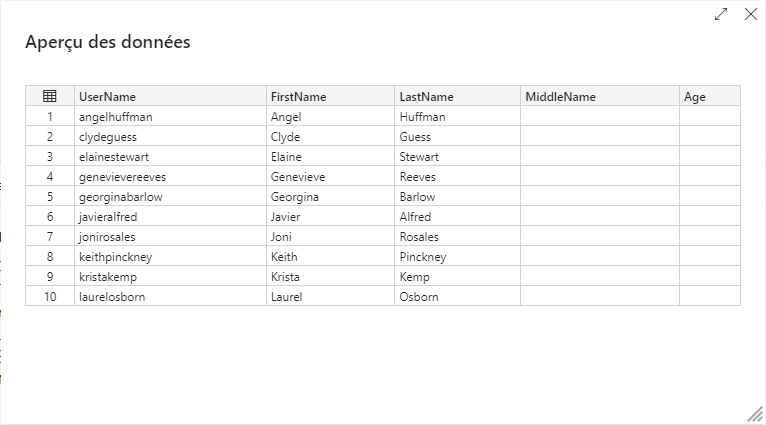
Vous devez voir les données sources comme dans l’écran ci-dessus.
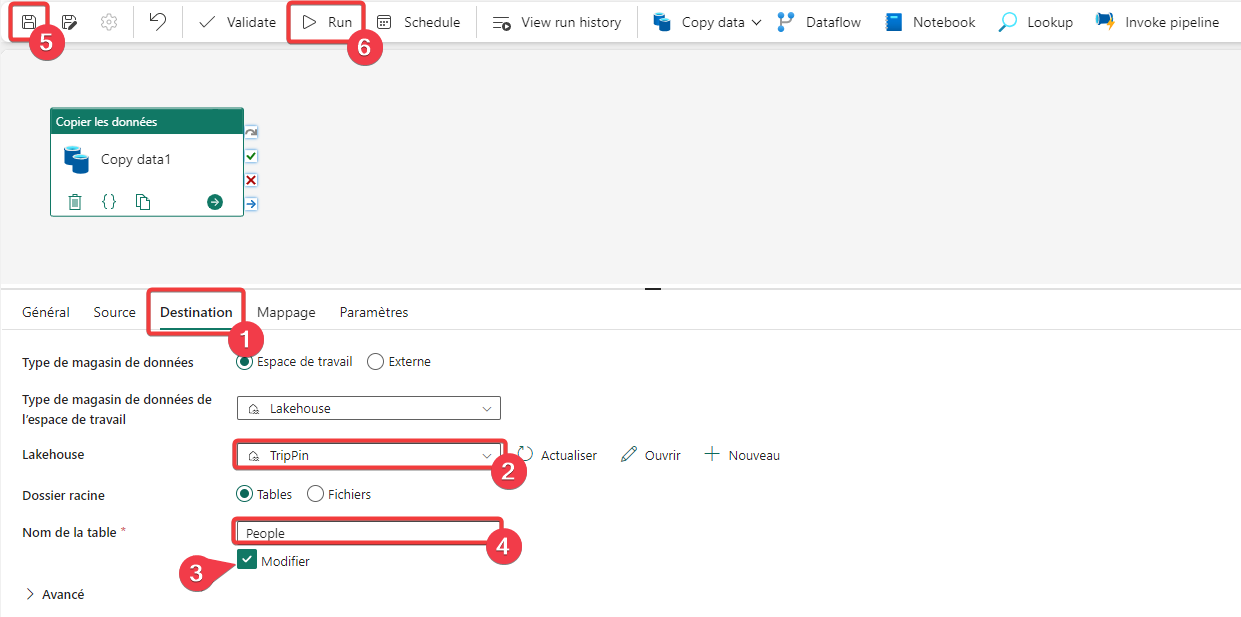
- Fermez la fenêtre d’aperçu et rendez-vous sur l’onglet Destination de l’activité de copie de données.
- Sélectionnez le lakehouse TripPin que l’on a créé précédemment.
- Cochez Modifier pour pouvoir saisir librement le nom de la table.
- Rentrez People pour le nom de la table.
- Enregistrez votre pipeline.
- Lancez une première exécution de votre pipeline.
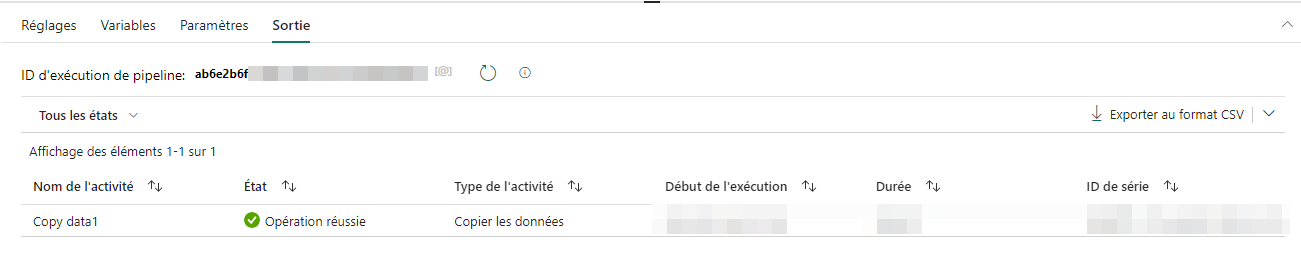
Vous pouvez voir les informations d’exécution du pipeline, la coche verte ✅ nous indique un succès.
Explorer le résultat de l’exécution du pipeline
Rendez-vous dans le lakahouse depuis l’espace de travail.
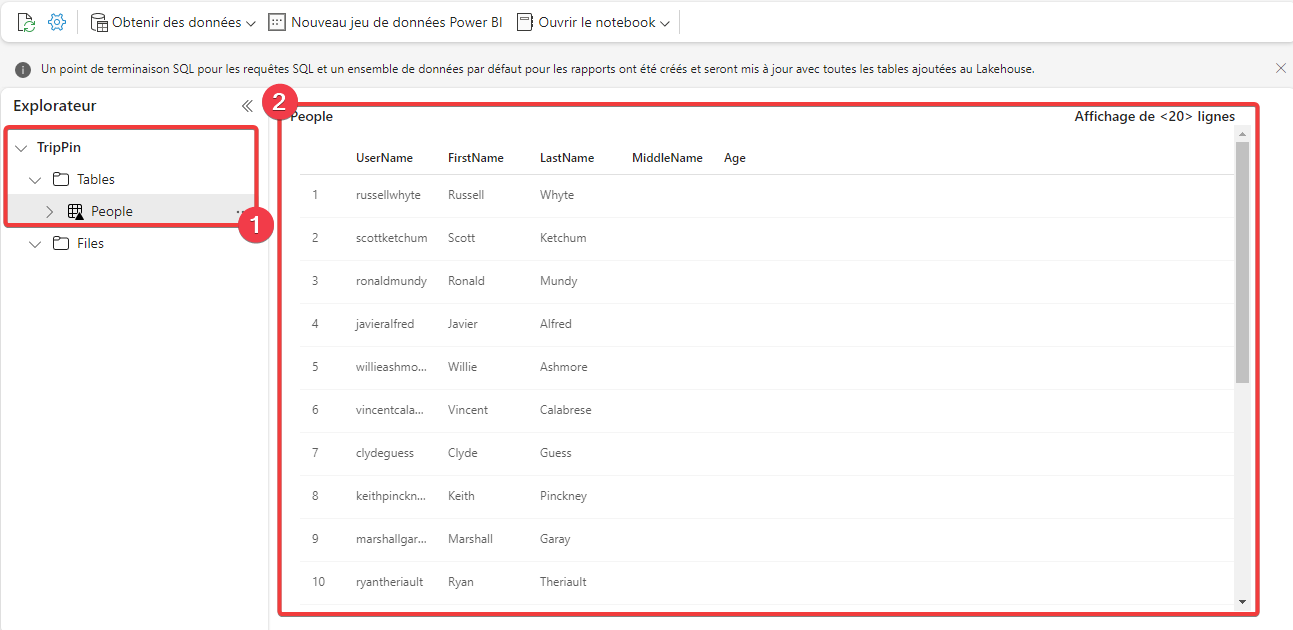
- Dans la partie Explorateur, vous pouvez voir votre table People. Cliquez dessus.
- Vous pouvez voir ici un aperçu du contenu de votre table.
Notre pipeline a envoyé une requête OData sur la source de données et à copier le résultat dans notre lakehouse sous la forme de fichier delta lake. C’est dernier ont automatiquement était mis à votre disposition de manière managée sous la forme d’une table pouvant être requêtée en SQL.
Copier plusieurs tables de données dans notre lakehouse
Sur la source de notre activité de copie, on peut constater que plusieurs chemins d’accès diffèrent son possible. Nous allons modifier notre pipeline afin de copier tous les chemins dans un seul pipeline.
Allez dans votre espace de travail et ouvrez le pipeline créé précédemment.
L’objectif est maintenant de réaliser une boucle permettant de copier l’ensemble des chemins d’accès possible de notre source de données, chaque chemin devant être stocké dans une table distincte.
Pour cela nous allons procéder en 2 étapes :
- Obtenir la liste des chemins disponible.
- Pour chaque élément de cette liste, utiliser une même activité de copie que l’on va variabiliser.
Nous allons maintenant ajouter une activité de type Lookup à notre pipeline.
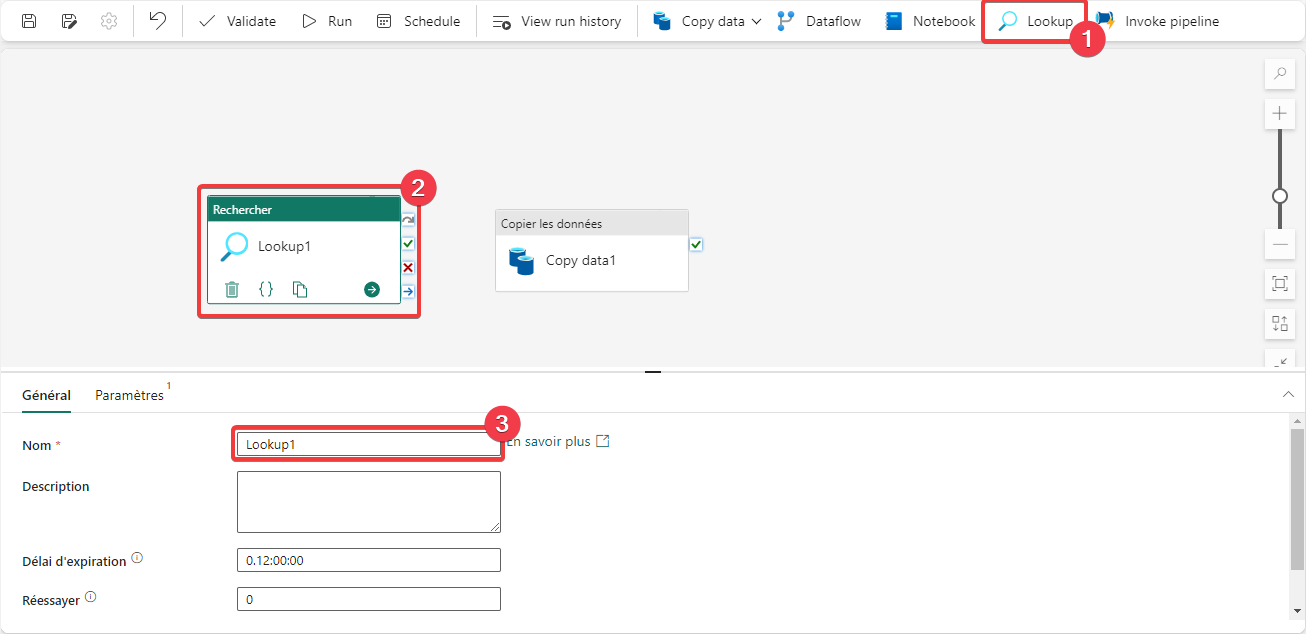
- Appuyer sur Lookup pour ajouter l’activité au pipeline.
- Sélectionnez l’activité pour accéder à ces propriétés.
- Renommez l’activité en Liste des chemins TripPin.
Pour obtenir la liste des chemins, nous allons interroger le service en mode HTTP (Requête Web).
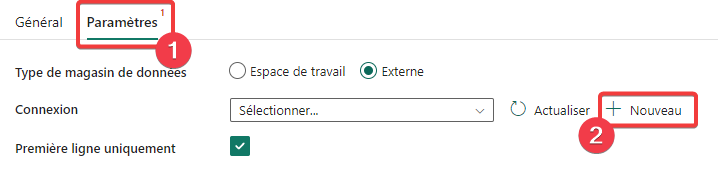
- Dans les propriétés de l’activité Liste des chemins TripPin, sélectionnez Source.
- Appuyez sur + Nouveau pour créer une nouvelle connexion.
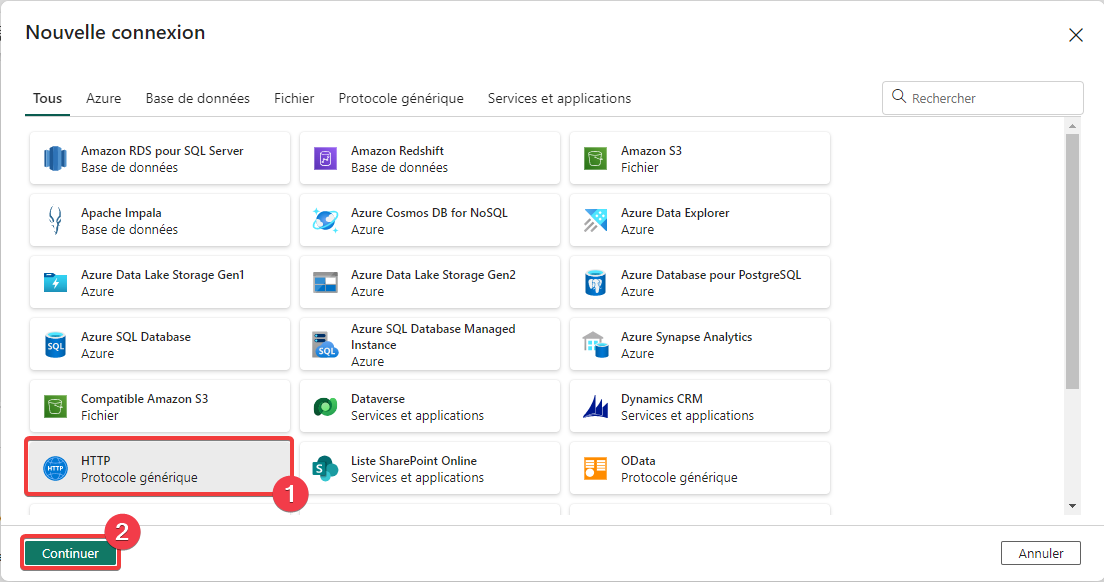
- Sélectionnez le connecteur HTTP.
- Appuyez sur Continuer.
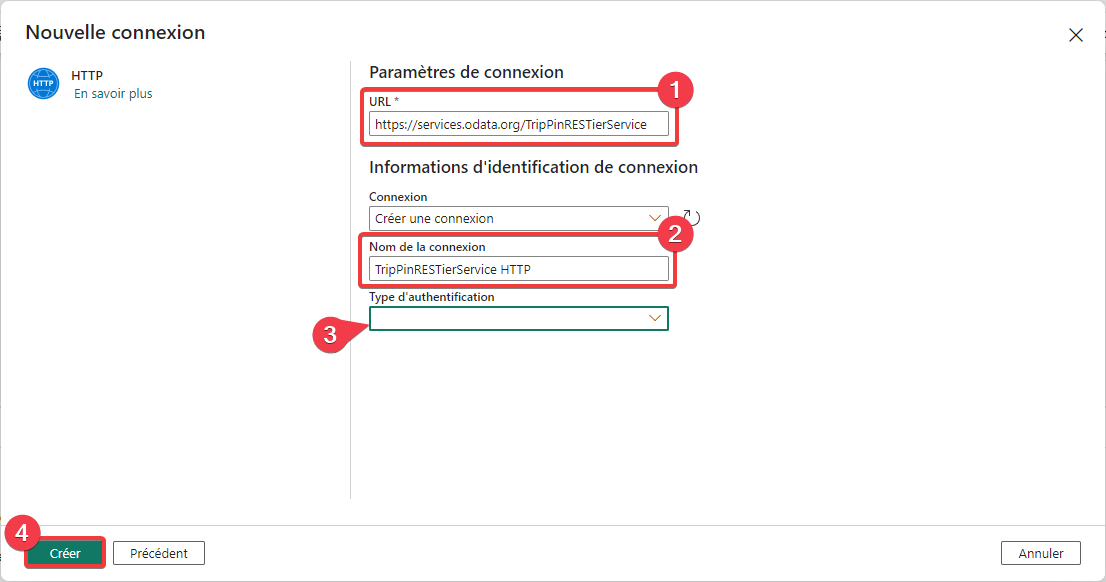
- Dans URL entrez l’adresse https://services.odata.org/TripPinRESTierService.
- Dans Nom de la connexion entrez TripPinRESTierService HTTP.
- Ne rien saisir dans Type d’authentification, on reste en mode anonyme.
- Appuyez sur Créer pour créer la nouvelle connexion.
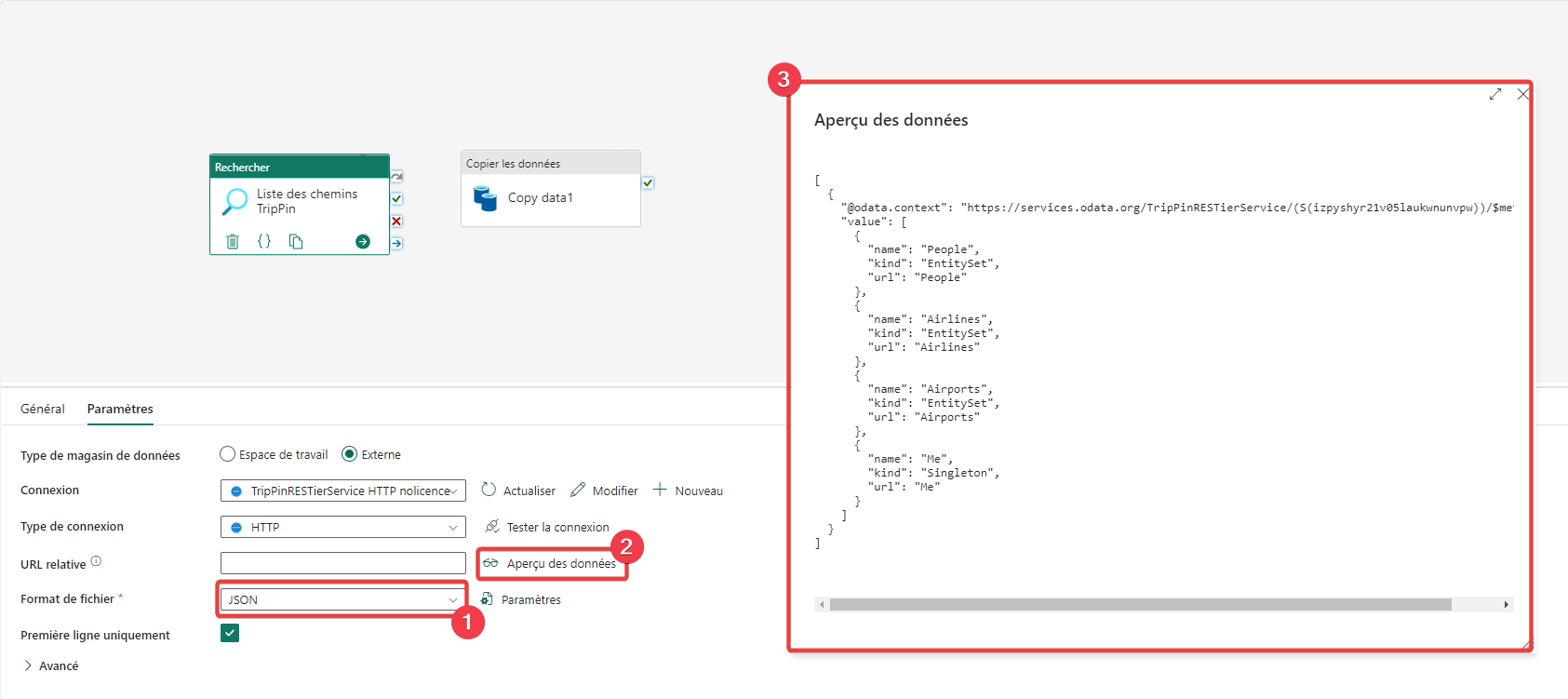
- Passez le format de fichier reçu en JSON.
- Cliquez sur Aperçu des données.
- Vous pouvez voir le résultat de l’appel de la requête HTTP. Vous pouvez constater que la liste des chemins est dans la clé value du document JSON sous forme de tableau, car dans un bloc entre crochets “[]”. Vous pouvez aussi voir que la valeur que l’on souhaite utiliser est url, elle permettra de variabiliser les appels. Fermez l’aperçu.
Pour traiter les éléments de la liste, nous allons ajouter une activité de type ForEach. Cette activité permet de faire une boucle pour chaque élément de la liste.
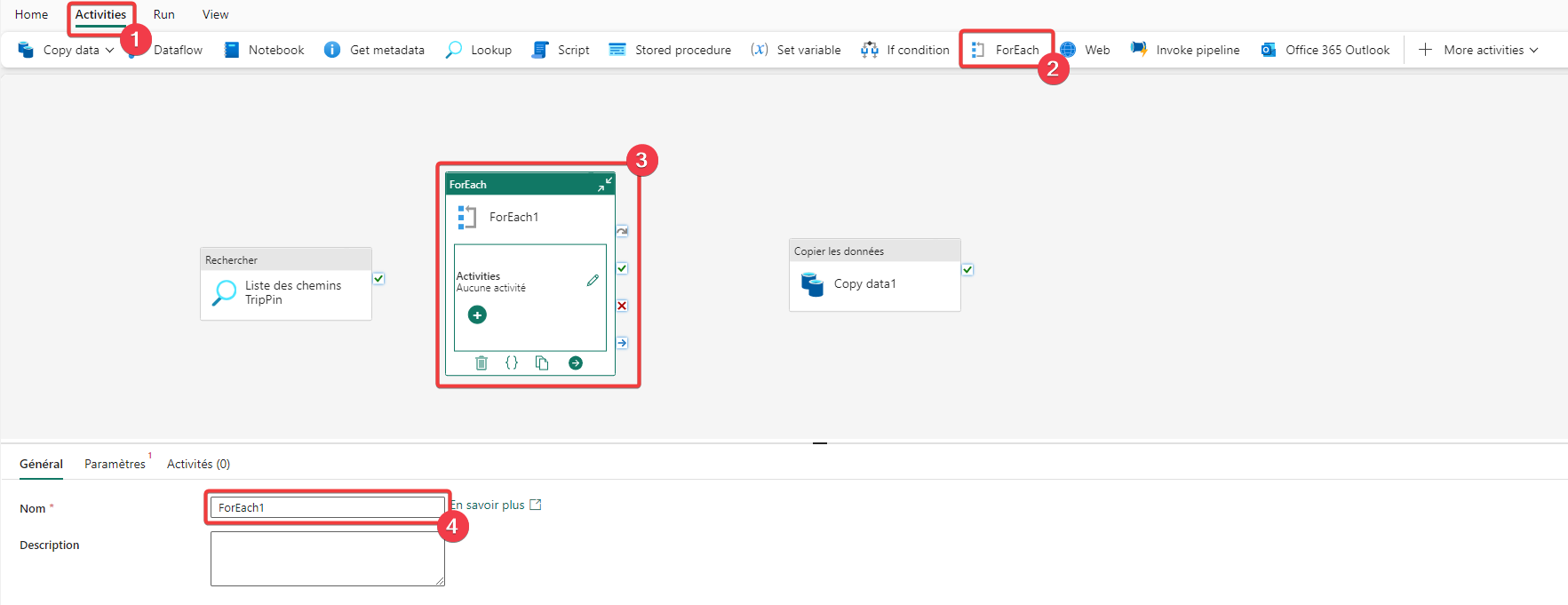
- Rendez-vous dans le menu Activities.
- Appuyer sur ForEach pour ajouter l’activité au pipeline.
- Sélectionnez l’activité pour accéder à ces propriétés.
- Renommez l’activité en Pour chaque chemin.
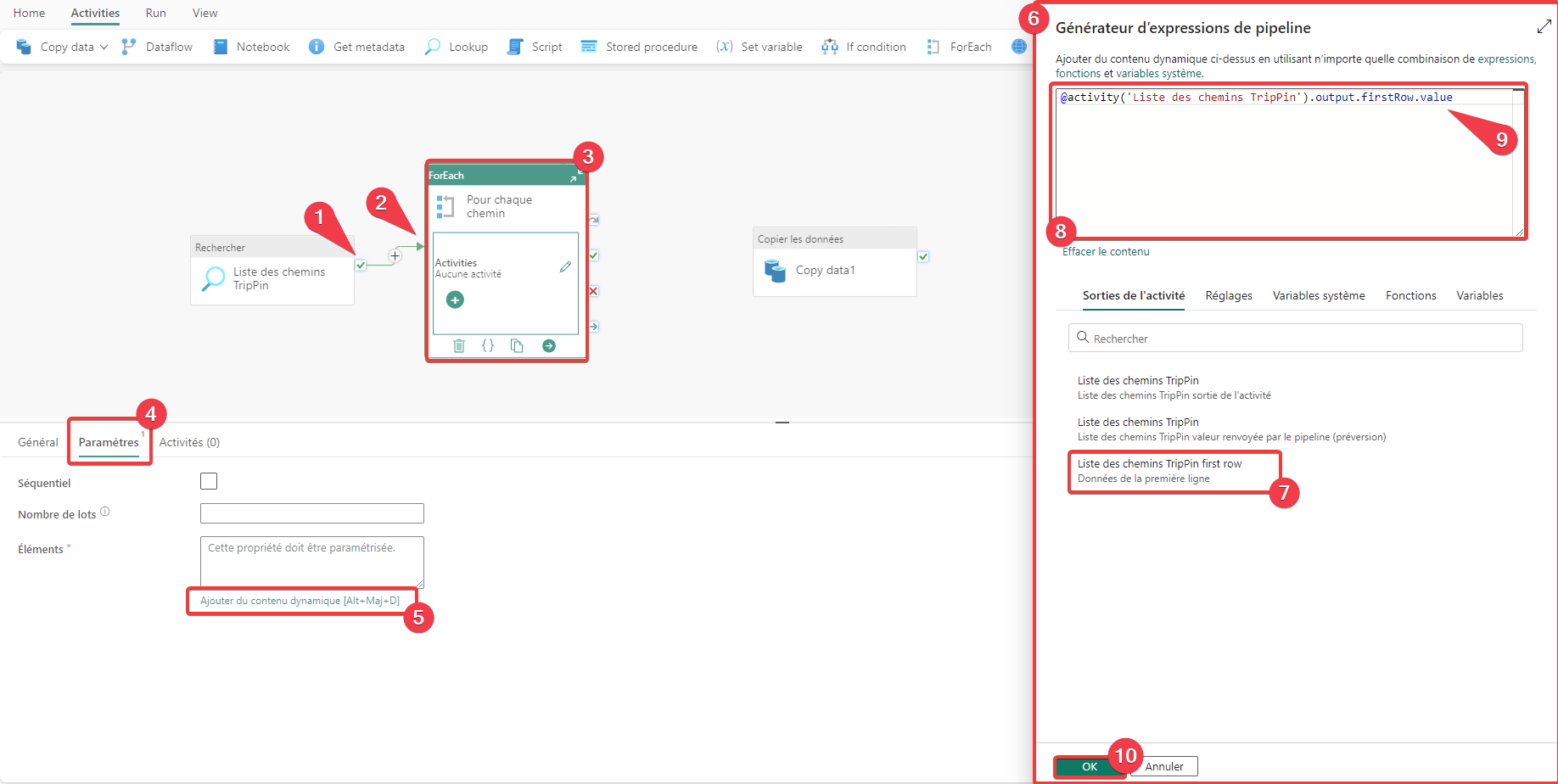
- Sélectionnez la coche verte sur l’activité Liste des chemins TripPin.
- Faite un glisser-déposer sur l’activité Pour chaque chemin. Vous avez créé un lien de dépendance entre les 2 activités. Pour chaque chemin s’exécutera après l’exécution réussie de Liste des chemins TripPin.
- Sélectionnez l’activité pour accéder à ces propriétés.
- Allez dans l’ongle Paramètres.
- La propriété éléments doit contenir la liste des éléments à parcourir pour la boucle ForEach. Appuyez sur le lien Ajouter du contenu dynamique.
- La fenêtre Générateur d’expressions de pipeline apparait. Cette fenêtre permet de variabiliser des propriétés via un ensemble de fonctions standard et les éléments spécifiques au pipeline. On ne peut référencer toutes les activités parentes à l’activité courante. Le lien de parenté a été réalisé à l’étape 2.
- Cliquez sur Liste des chemins TripPin first row, et le texte @activity(‘Liste des chemins TripPin’).output.firstRow apparait dans la zone d’édition.
- Dans cette zone d’édition, vous pouvez saisir l’expression dynamique.
- Rappelez-vous dans le JSON renvoyé par l’activité Liste des chemins TripPin la liste des chemins ce trouve dans la propriété value. Nous allons donc rajouter .value à l’expression afin d’indiquer où se trouve notre liste. Vous devez donc avoir @activity(‘Liste des chemins TripPin’).output.firstRow.value comme valeur.
- Appuyez sur OK pour fermer.
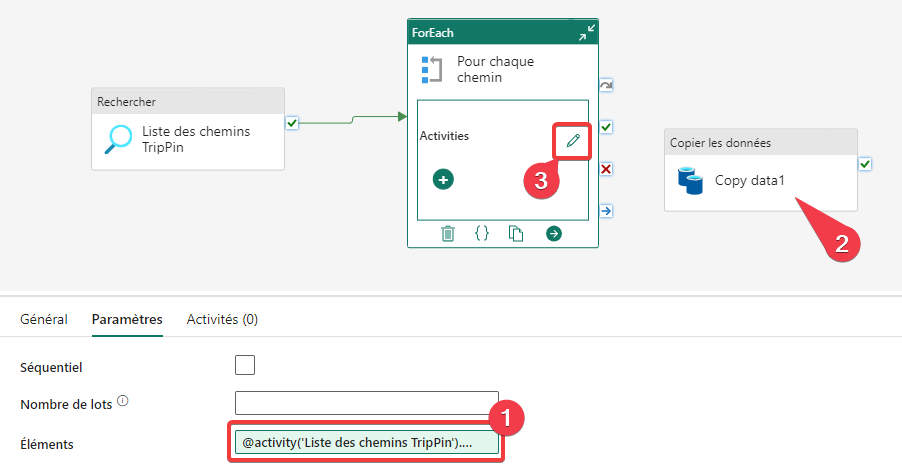
- La propriété Eléments de l’activité Pour chaque chemin à maintenant un fond vert pour vous indiquer qu’il s’agit d’une expression.
- Nous allons maintenant déplacer l’activité de copie dans la boucle. Faites un clic droit sur l’activité de copie et choisissez Couper.
- Sur l’activité Pour chaque chemin sélectionnez l’icône en forme de crayon pour accéder à la zone d’édition intérieure de l’activité.
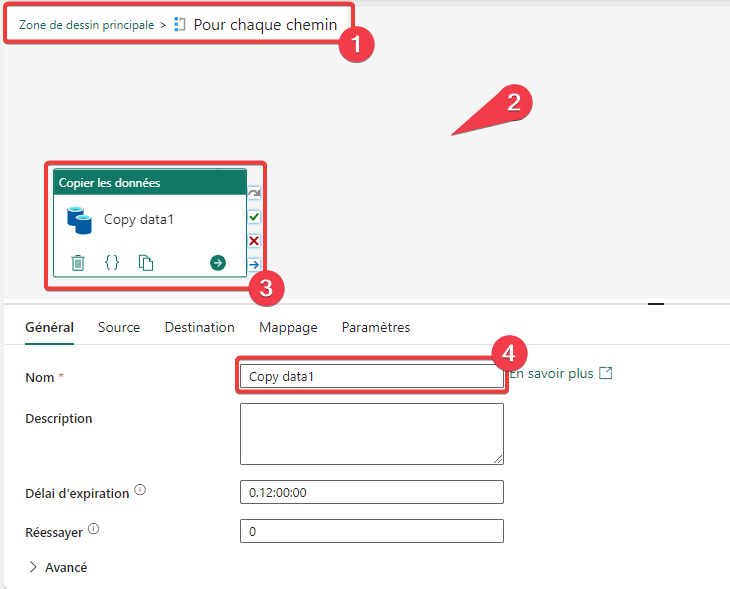
- Vous pouvez à tout moment voir où vous êtes. Quand vous voudrez retourner dans la zone de dessin principale vous pourrez clique sur le lien pour y accéder.
- Faite un clic droit dans un endroit vide de la zone de dessin et choisissez Coller. Votre activité de copie apparait.
- Sélectionnez l’activité pour accéder à ces propriétés.
- Renommez l’activité en Copie du chemin.
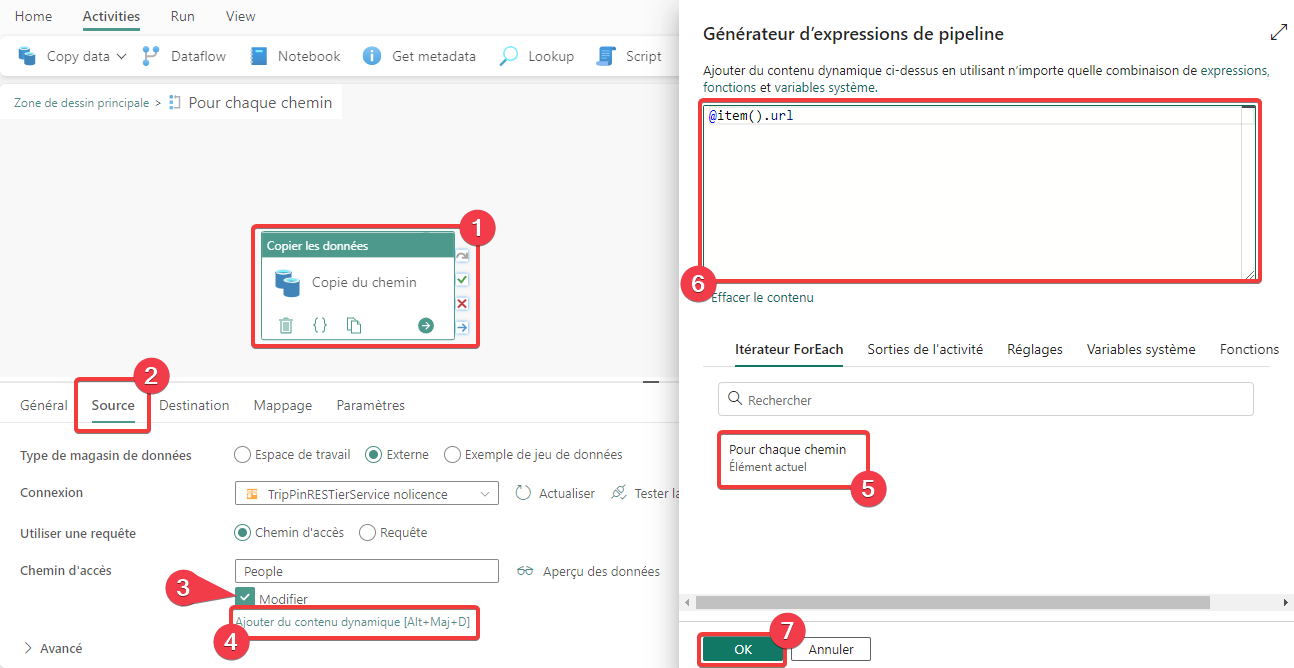
- Sélectionnez l’activité pour accéder à ces propriétés.
- Allez dans l’ongle Source.
- Cochez Modifier pour pouvoir saisir librement le chemin.
- Appuyez sur le lien Ajouter du contenu dynamique. S’il n’apparait pas positionné, cliquez dans la zone de saisie du chemin d’accès.
- Cliquez sur Sur chaque chemin. Le texte item() apparait dans la zone d’édition. Cette valeur est la référence de l’élément en cours dans la lecture de la liste.
- Quand on a regardé l’aperçu, la propriété des éléments de la liste que l’on s=ouhaité lire était url. Nous allons donc l’indiquer, le texte complet de l’expression est @item().url.
- Appuyez sur OK pour fermer.
Nous allons maintenant variabiliser la destination.
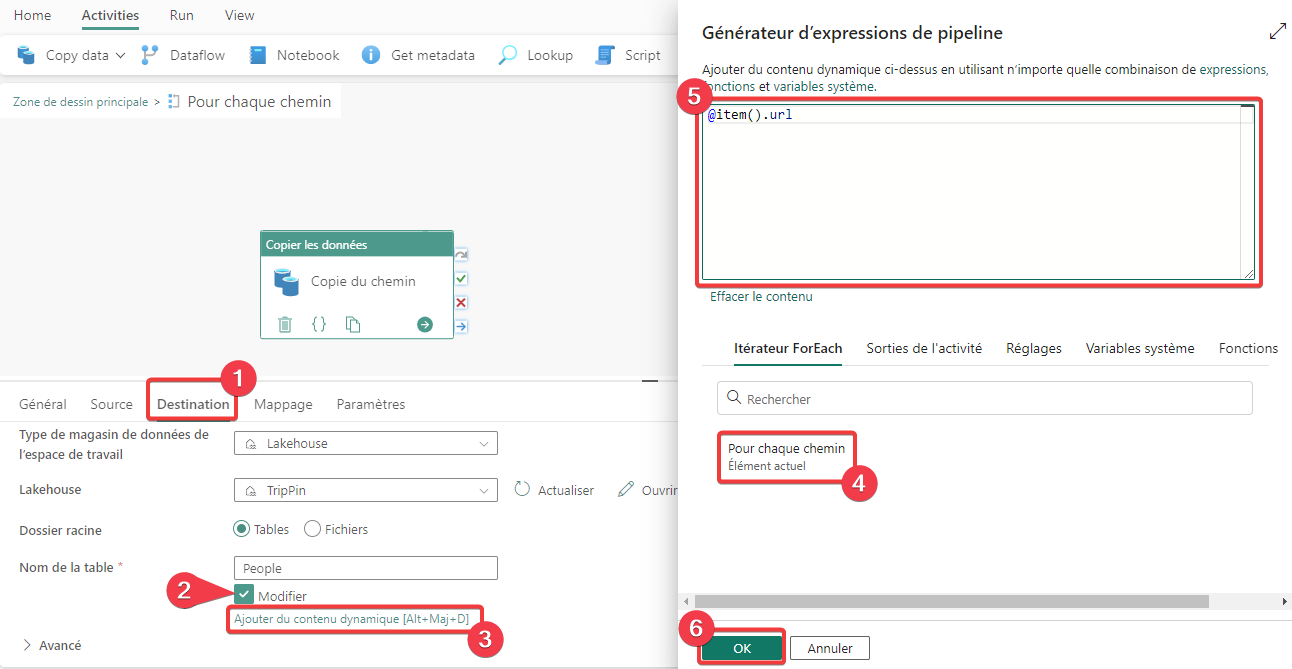
- Allez dans l’ongle Destination.
- Cochez Modifier pour pouvoir saisir librement le nom de la table.
- Appuyez sur le lien Ajouter du contenu dynamique. S’il n’apparait pas positionné, cliquez dans la zone de saisie du nom de la table.
- Cliquez sur Sur chaque chemin. Le texte item() apparait dans la zone d’édition. Cette valeur est la référence de l’élément en cours dans la lecture de la liste.
- Quand on a regardé l’aperçu, la propriété des éléments de la liste que l’on s=ouhaité lire était url. Nous allons donc l’indiquer, le texte complet de l’expression est @item().url.
- Appuyez sur OK pour fermer.
Nous allons maintenant sauvegarder et exécuter le pipeline, aller dans le menu Home et appuyer sur l’icône de sauvegarde puis d’exécution du pipeline.
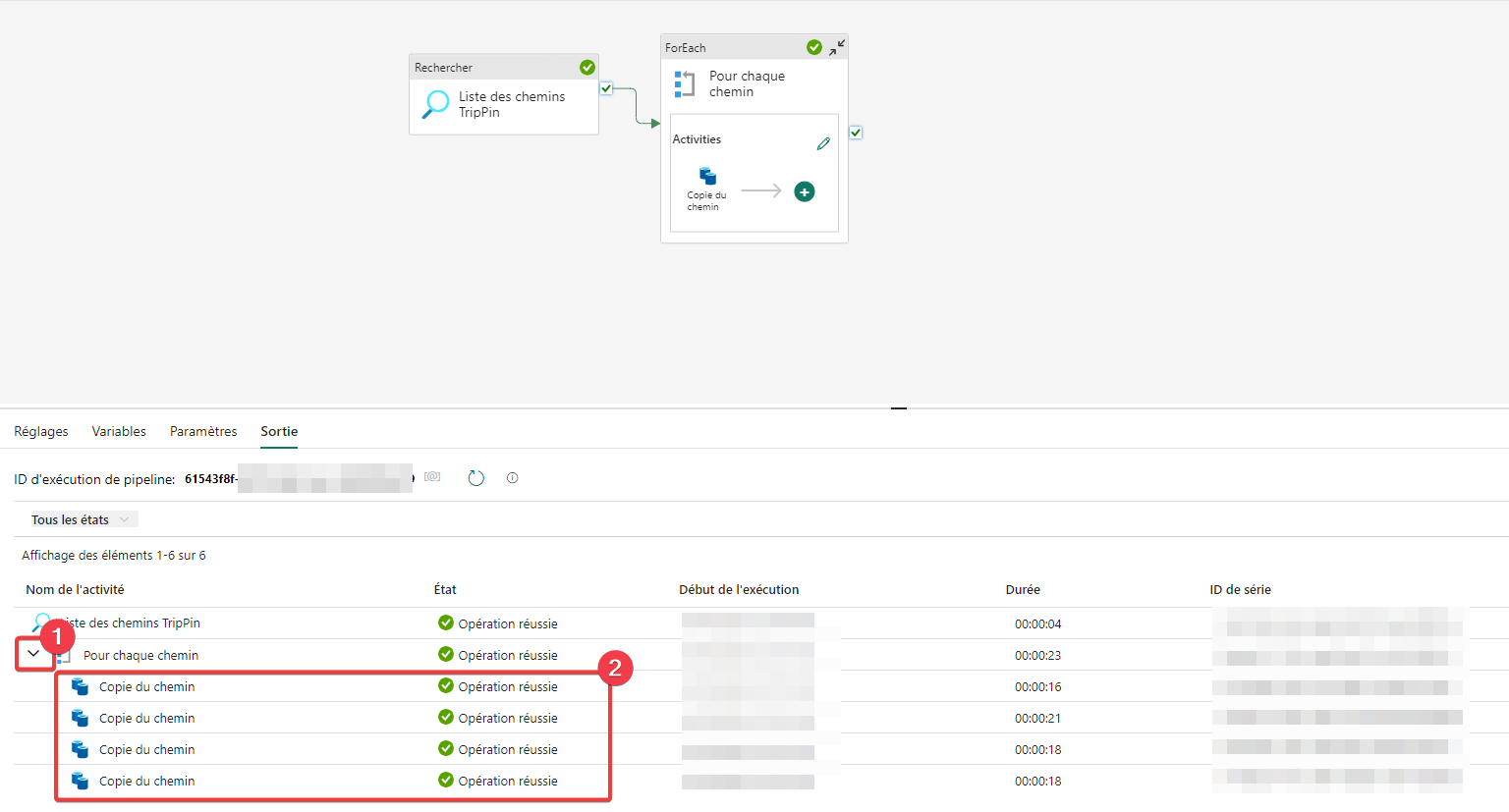
- Ouvrez le chevron pour voir le détail de l’exécution de la boucle
- Vous pouvez constater qu’il y a eu plusieurs exécutions différentes de l’activité de copie.
Rendez-vous dans le lakahouse depuis l’espace de travail.
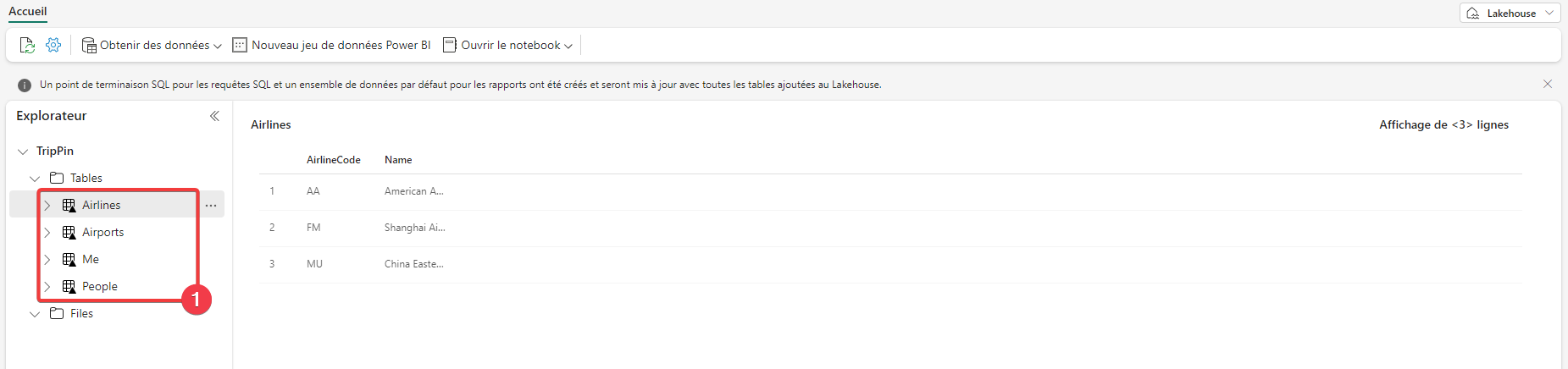
- Dans la partie Explorateur, vous pouvez voir que toutes les tables on était créées.
Bravo vous avez créer votre premier pipeline.
L’exemple présenter permet seulement d’effleurer les possibilités des pipelines. Comme vous devez le présentir, cet outil offre un grand nombre de possibilités pour le traitement de vos données.
Merci de votre attention.