
Dans cet article je vous présente le concept de Datalake ou lac de données en bon français. Un datalake est la fondation d’un projet data moderne, vous le retrouverez dans la plupart de vos futurs projets.
Contexte
Comme je vous l’ai présenté dans ce précédent article, le datalake est un élément clé des projets data moderne. Je me propose maintenant de vous présenter plus en détail ce qu’est un datalake, comment on le structure et comment on peut s’en servir.
Contrairement à ce que l’on pourrait croire, les datalakes ne sont pas réservés aux gros projets de data et leur philosophie d’usage peut-être reprise dans tout projet data.
Le stockage
Lorsque l’on parle datalake on parle avant tout d’un stockage de données pouvant accepter tout type de format de données.
En général lorsque l’on parle de datalake on pense stockage cloud, l’avantage de ce type de stockage est sa capacité à être étendue en fonction de vos besoins et de vos finances. Bien que cette solution est la plus souple, on peut très bien créer un datalake en dehors du cloud.
Les principaux types de stockages pour vos datalakes peuvent être :
- En cloud dans l’écosystème Microsoft
- Azure Datalake Gen 2
- Sharepoint
- Sur vos infrastructures locales
- Un partage réseau
- Un disque dur
L’organisation
Une fois la solution de stockage choisie, il est indispensable de réfléchir à l’organisation de votre datalake.
Sans rigueur votre lac de données deviendra un marais de données (dataswamp).
Les zones
Bien que chacun puisse créer l’organisation qu’il souhaite, on retrouve en général les 3 zones suivantes :
- Bronze : Cette zone sert de landing zone pour les données, elle permet d’écrire les données brutes reçues dans le datalake. Aucune transformation n’est réalisée sur les données.
- Silver : cette zone permet de raffiner les données de la zone Bronze et d’effectuer les traitements de préparation de données parmi lesquels on retrouve :
- La transformation de données en un format de table avec
- Le nommage des colonnes
- Le typage des colonnes
- La détection des anomalies
- La détection des problèmes de qualité
- La transformation de données en un format de table avec
- Gold : cette zone contient les données avec le plus haut niveau de raffinage, on retrouve par exemple
- Des données modélisées pour le reporting (modèle en étoile).
- Des données préaggrégées.
Le nom de ces zones peut varier, mais leur usage reste. D’autres zones peuvent être créées en fonction de vos besoins spécifiques, par exemple une zone sandbox pour des expérimentations.
Les coûts de stockage étant relativement bas, en général, les traitements permettant le raffinage des données d’une zone à l’autre ne suppriment pas les données traitées. Ainsi si vous traitez des données sources en utilisant 10 champs sur 50 dans le fichier brut et que vos besoins évoluent, vous aurez toujours la possibilité de retraiter l’ensemble des données brut pour répondre à vos nouveaux besoins.
Les partitions
Le partitionnement des données va vous permettre de ranger vos données de manière précise. Quand on parle de partitionnement, il s’agit simplement de mettre vos fichiers dans des dossiers et sous dossier différent. L’avantage du partitionnement est notamment de pouvoir accéder rapidement à des données en ne lisant que les fichiers présents dans les partitions qui nous intéressent.
Vous pouvez mixer les partitions comme vous le souhaitez.
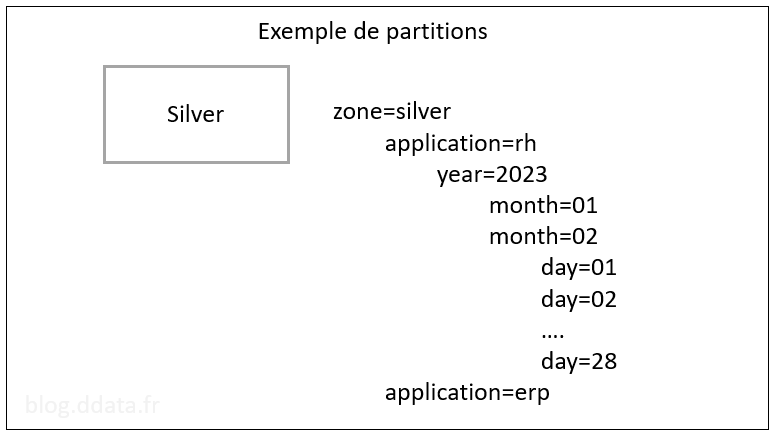
En général, on crée des partitions en créant des dossiers sous la forme NomPartition=ValeurPartition.
Les principaux partitionnements que vous utiliserez sont :
- Par source de données avec par exemple des dossiers sous la forme /service=rh/application=monapplication
- Par version de traitement ou de format de fichier avec par exemple des dossiers sous la forme /version=2.0
- Par date avec par exemple des dossiers sous la forme /year=2023/month=02/day=26
Les principaux formats de données
Votre datalake va contenir des fichiers, voici quelque format classique que vous y trouverez :
- Parquet : C’est le format roi des datalakes, il s’agit d’un format de fichier dédier aux données analytiques, il conserve le nom et le type de données des colonnes et compresse les données contenues dans le fichier.
- CSV : Format classique d’extraction de données, il contient le nom des colonnes, mais les séparateurs utilisés peuvent varier en fonction de l’origine régionale du fichier (les séparateurs US et FR sont différents).
- Excel : Est-ce besoin de le présenter ? Un incontournable dans tous projets data.
- json, yaml, xml : Il s’agit en général de fichiers issus de traitement automatisé tel des API. Ces fichiers sont semi-structuré.
- log : les fichiers de log pourront être stockés longtemps et conserver une possibilité de traitement dans un datalake. Ces fichiers sont en général semi-structuré.
- Binaire : les vidéos et images sont des formats de données binaires, ils peuvent contenir certaines métadonnées exploitables directement (coordonnée GPS pour une photo par exemple), mais en général un traitement de type IA et nécessaire pour qualifier le contenu du fichier.
La sécurité
La sécurité est un point clé de votre datalake, elle est portée par les possibilités offertes par la solution de stockage que vous avez choisie.
Dans tous les cas, penser à créer plusieurs datalakes si vous avez des besoins forts de sécurité, une séparation des données peut prémunir contre des niveaux de droits inadéquats accordés à certain utilisateur.
Traitement des données
Le traitement des données d’un datalake fera l’objet d’un prochain article.
Merci de votre attention.