
Vous avez décidé de vous lancer dans un projet Power BI et vous vous demandez comment vous y prendre ? Je vous propose de vous présenter, dans les grandes lignes, comment mener un projet BI.
Contexte
Vous débutez dans la réalisation d’un projet BI ?
Bonne nouvelle, quel que soit l’outil que vous utiliserez un projet BI se réalise toujours de la même manière. Je vous propose dans cet article une présentation simple de la réalisation d’un projet BI, dans le cadre de l’utilisation de Power BI.
Les phases d’un projet BI
Avant tout, un projet BI n’est pas un projet statique, mais un projet en perpétuel enrichissement. Vous allez commencer en intégrant certaines données, puis au fil des itérations du projet vous allez améliorer votre projet en répétant les différentes phases du projet qui sont les suivantes :
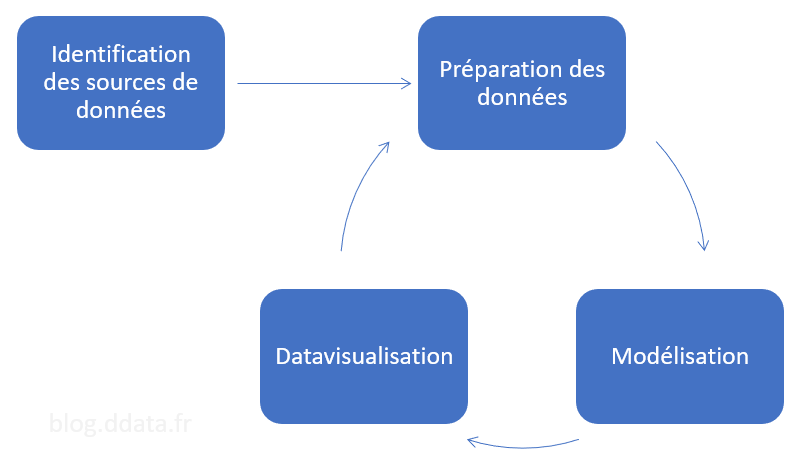
Phase 0 : identification des sources de données
Lors de cette phase, vous identifiez les sources de données que vous souhaitez intégrer dans votre projet. Pensez déjà à la méthode que vous utiliserez pour rafraichir la donnée en privilégiant les solutions automatisables.
Phase 1 : préparation des données
Lors de cette phase, vous allez mettre en place un processus de traitement de données que l’on appelle ETL dans les projets BI, c’est l’acronyme anglais de Extract Transform Load. Dans le cadre d’un projet Power BI vous utiliserez l’outil Power Query, intégrer à Power BI, pour réaliser cette phase du projet. Voici les tâches à réaliser :
- Extraire les données : l’objectif est de lire les données depuis la source de données (Base de données, fichier Excel, API Web ou autres). Un projet BI doit TOUJOURS être en lecture seule sur la source. On ne réalise pas de modifications dans la source, mais dans une copie lors de l’étape de transformation.
- Transformer les données : Lors de cette phase nous allons transformer les données sources notre objectif est de créer une tables de faits ou une table de dimension pour notre modèle de données en étoile. Les principales étapes consisteront à :
- Définir les colonnes que l’on conserve
- Nommer les colonnes dans le langage métier.
- Mettre le bon type de données aux colonnes (texte, entier, date …).
- Nettoyer les données dans les lignes si besoin.
- Restructurer les données si besoin afin de créer des tables de faits ou de dimensions.
- Enrichir notre table avec d’autres sources de données.
- Charger les données : Maintenant que nos données sont prêtes nous allons les charger dans Power BI, pour cela on utilise le bouton Fermer et appliquer de Power Query.
À la fin de cette étape, Power BI contient un ensemble de tables chargées que vous allez utiliser lors de la prochaine phase.
Phase 2 : modélisation des données
Vos données sont maintenant disponibles sous forme de table dans Power BI. L’objectif est maintenant de réaliser un modèle de données métier qui sera utilisé par vos utilisateurs dans le cadre d’une self-service BI par exemple.
Le modèle de données est essentiel, il est composé :
- Des tables de données reçues de Power Query.
- De relations entre les tables.
- De mesures et colonnes calculées créées en DAX.
Un bon modèle de données est un modèle que les utilisateurs comprennent rapidement. Il doit être documenté afin que la définition des mesures soit partagée et comprise. Idéalement il ne doit pas y avoir d’éléments techniques visibles de l’utilisateur de modèle.
Le langage DAX s’appuie sur un modèle en étoile afin d’exprimer toute sa puissance, si vous ne comprenez pas de quoi je parle, documentez-vous avant 😁.
Phase 3 : présentation des données
On arrive à la phase visible du projet. Vous allez utiliser le modèle de données créer lors de la phase précédente pour alimenter les différentes visualisations de votre futur rapport. Naturellement vous ne trouverez pas immédiatement le bon indicateur ou vous découvrirez qu’il vous manque des données. Vous devrez alors repartir dans le cycle afin de’enrichir votre modèle.
Self-service BI vs BI d’entreprise, quelles différences ?
Si un projet BI se fait toujours de la même manière, quelle est donc la différence entre la self-service BI et BI d’entreprise ?
C’est principalement une question d’approche projet : qui fait quoi ? Mais aussi cela dépend aussi souvent de la source de données.
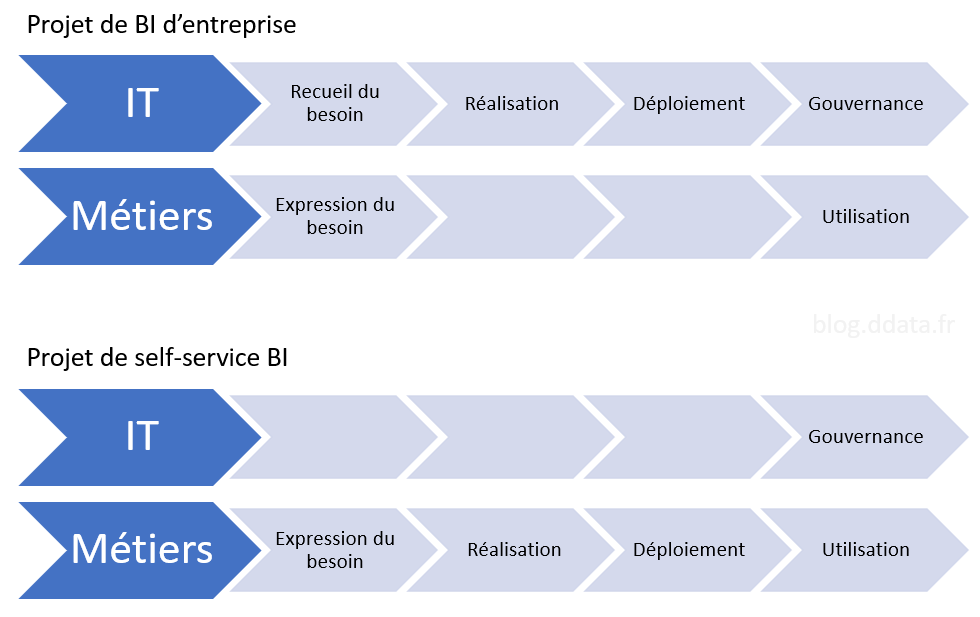
Responsabilité de réalisation
Un projet BI d’entreprise est souvent mené par l’IT de l’entreprise. Il s’agit de mettre à disposition des modèles de données et des rapports respectant des standards de qualité. La méthodologie de projet et les techniques utilisées pour le développement de logiciel sont utilisées pour la réalisation du projet BI d’entreprise. L’IT mène ce genre de projet dans le cadre de ses autres activités, et comme pour tout projet informatique vous rencontrerez notamment les inconvénients suivants :
- Mauvaise compréhension de besoin.
- Mauvaise expression du besoin.
- Modification du besoin entre la collecte de ce dernier et la mise à disposition de résultat.
- Délai de réalisation (toujours) trop long. Et comme la loi de Murphy s’applique, vous avez de grande chance de tous les rencontrer à chaque fois.
Un projet en self-service BI est réalisé par un service ou une personne ayant de bonnes connaissances du métier et des données, car elle travaille déjà avec régulièrement. Cette personne doit apprendre l’utilisation d’un outil comme Power BI et réalise le projet BI par elle-même ou avec de l’accompagnement.
On peut représenter simplement cette différence ainsi :
Nature des sources de données
Un projet BI d’entreprise a pour objectif de mettre à disposition du plus grand nombre des données d’entreprise. En général il permet d’accéder à l’ensemble des données dans un seul modèle intégrant les contraintes de sécurité d’accès aux données. De plus les sources primaires de type base de données ou API demandent des compétences spécifiques que l’on retrouve dans les services IT. Enfin ce type de projet utilise fréquemment des couches intermédiaires de données permettant une première modélisation. Cette couche est fréquemment sous la forme d’un datawarehouse ou d’un datalakehouse pour les architectures modernes dans le cloud.
Un projet en self-service BI est en général fait avec les moyens du bord, les données utilisées sont souvent des données spécifiques à un service en termes de scope. Vous n’avez pas forcément l’accès à la donnée source primaire en termes de sécurité ou de connaissance. Dans ce cas des extractions limitées à un sous-ensemble de données sont utilisées pour ces projets qui de fait ne pourront pas répondre à des besoins d’entreprise.
Au-delà de cette organisation
Entre self-service BI et BI d’entreprise on peut imaginer d’autres niveaux de partage de responsabilité, on parle parfait de self-service managed BI pour des scénarii dans lesquels l’IT développe et modélise les couches bases de données et les mets à la disposition des métiers qui peuvent être en responsabilité de l’enrichissement, par exemple l’ajout des objectifs, mais aussi de la réalisation des rapports. Libre à vous d’adapter le produit à votre mode de fonctionnement.
Conclusion
Retenez qu’un projet BI n’est jamais un projet statique. Vos données bougent, vos besoins changent et plus vous exposez de la donnée, plus de nouveaux besoins apparaissent comme par magie. Vous devez donc être agile, quand vous réalisez une tâche pensez à celui qui devra venir après vous dans quelque temps pour changer des choses. Votre Moi futur vous remerciera, car cette personne c’est probablement vous même.
Merci de votre attention.